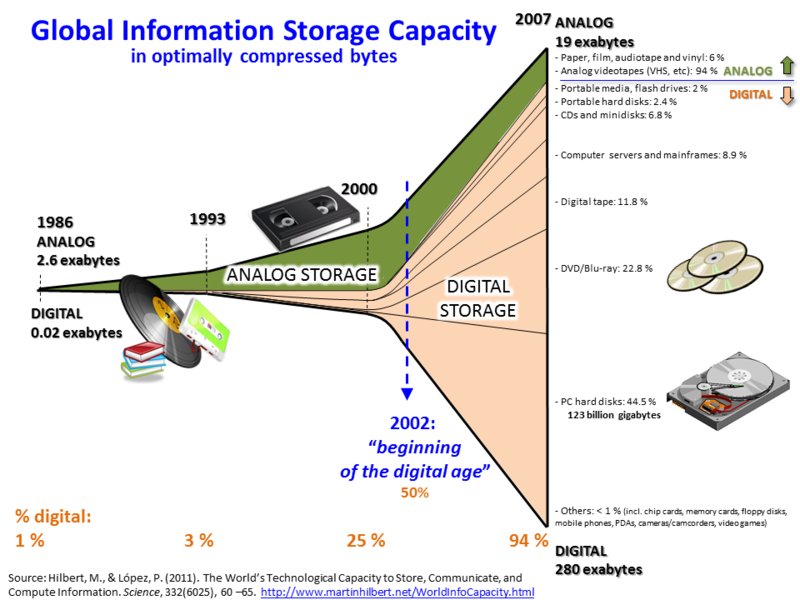
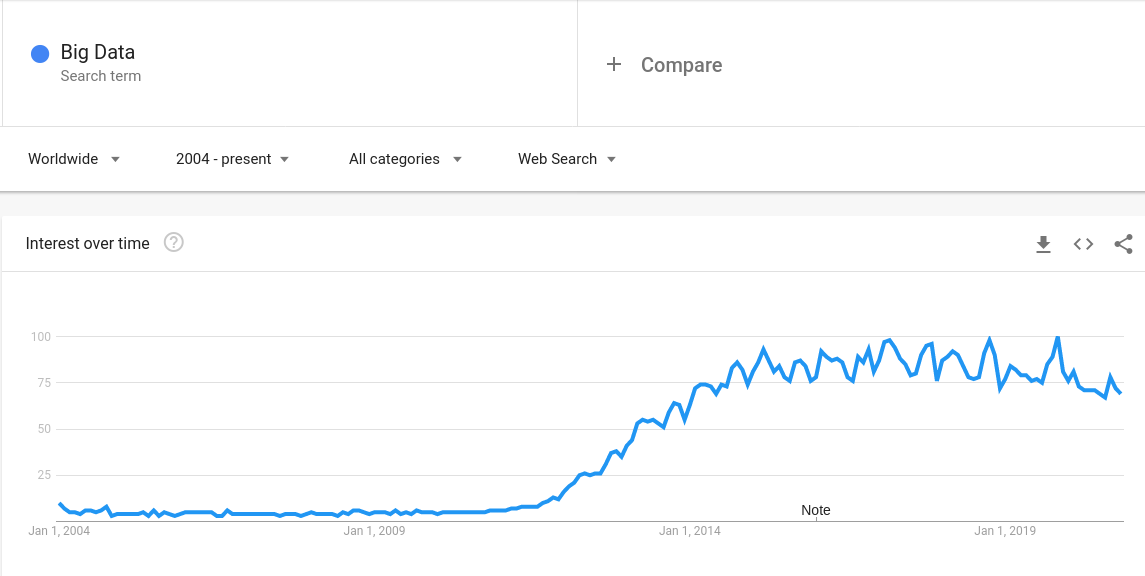
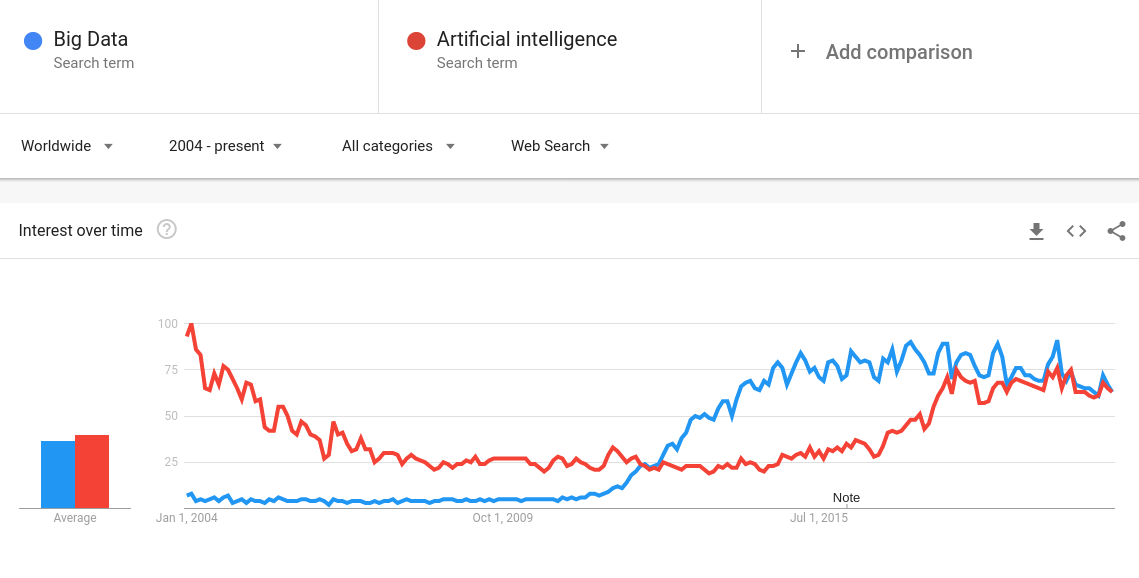
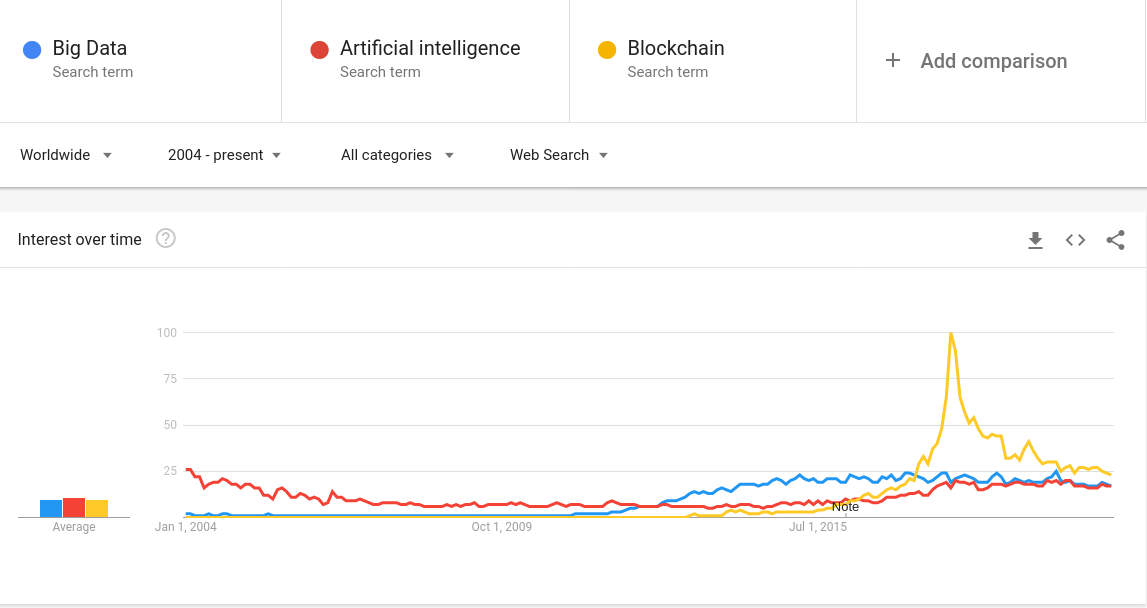
Machine à calculer de Blaise Pascal
- Invention au 17e siècle : Calculatrice mécanique à six chiffres.
- Utilisation scientifique : Contribution à la résolution de problèmes mathématiques
complexes.
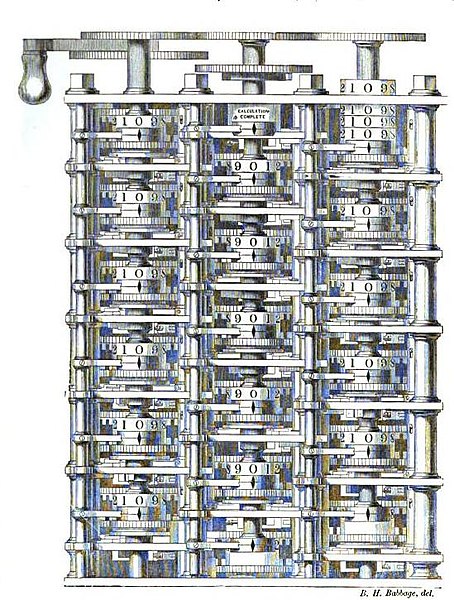
Machine à Différences de Charles Babbage
- Conception au 19e siècle : Machine mécanique pour automatiser les calculs.
- Précurseur des ordinateurs : Influence sur le développement des ordinateurs modernes.
Automatisation des calculs : Réduction du temps nécessaire pour effectuer des calculs
complexes.
Avancées scientifiques : Facilitation de la recherche scientifique grâce à des outils de
calcul
plus efficaces.