Enseignant-Chercheur, Conception Logicielle et Big Data, CPE Lyon
Intérêts et thèmes de recherche: Représentation de connaissances, le web
sémantique,
les services web, l'intégration de données, l'entrepôt de données, les systèmes
distribués,
système d'information géographique
Cours: Programmation en C, Algorithmes en C, Data Mining et Machine Learning,
Intelligence Artificielle et Deep Learning, Systèmes d'exploitation et Programmation
Concurrente, Langages Web
Thèse: Intégration des données issues de services web
HDR : Des regards sémantiques pour des villes intelligentes, durables et
inclusives
Data Mining
Objectifs
Maîtriser les techniques de représentation, manipulation et prétraitement des données
pour en
optimiser l'utilisation.
Appliquer des méthodes avancées de traitement des données pour extraire des informations
pertinentes et exploitables.
Construire des modèles de traitement par apprentissage machine afin d'analyser et de
prédire
des tendances à partir de données.
Intégrer les données ouvertes liées dans vos analyses pour enrichir vos résultats.
Composition du Module
📖
8h
Cours
💻
16h
TP & Projet
60%
Examen
40%
Projet
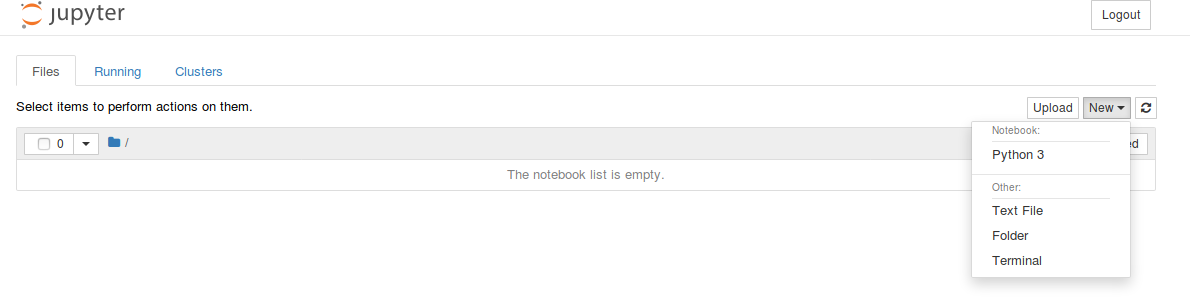
Environnement de Programmation
🐧
Linux/Ubuntu
Jupyter
🐼
pandas
📈
matplotlib
🔬
scikit-learn
Options d'installation
Ubuntu natif
VirtualBox + Ubuntu
Organisation
Cours
Sessions interactives
Questions toutes les 20-30 min
60% de la note
TP & Projet
3 TP + 1 Projet
Travail en binôme
Soumission en ligne
40% de la note
Data Mining
Devoir surveillé (DS): 60%
Examen: En-ligne sur E-campus
Durée: 2 heures. Total: 20 points
Documents: autorisés ; Types de documents autorisés: tous les documents autorisés
Calculatrices: non autorisées
Utilisation de l'internet: non autorisée
Dépôt supplémentaire: disponible pour les fichiers personnels
Vous recevrez un courrier détaillé avant l'examen
Data Mining
Travaux pratiques et projet
Le projet sera évalué.
La date limite de soumission est précisée sur e-campus.
Il est fortement conseillé de travailler en binôme pour favoriser la collaboration et
l'efficacité.
Planning: Cours
Cours 12h
3 février
Cours 22h
4 février
Cours 32h
10 février
Cours 42h
11 février
Planning: Travaux Pratiques
TP 1 + Projet 3 et 4 février
TP 2 + Projet 10 et 11 février
TP 3 + Projet26 février
Projet4 mars
Data Mining
Travaux pratiques
Exploration approfondie de Jupyter, une plateforme interactive prisée pour l'analyse de
données. Création de notebooks interactifs, intégration de code et de visualisations pour une
analyse
interactive des données.
Expérience pratique avec des jeux de données ouvertes, permettant une compréhension
concrète
des enjeux liés au traitement de données. Application de techniques avancées pour extraire des
insights
significatifs à partir de données hétérogènes.
Data Mining
Soumission: Travaux pratiques et Projet
TP
Points
TP 1
Non noté
TP 2
Non noté
TP 3
Non noté
Projet
20 points
Seul le projet compte pour l'évaluation (20 points), bien que la participation aux TP 1-3 reste
vivement recommandée.
Data Mining
Travaux pratiques
Chaque TP comporte plusieurs exercices. Chaque
exercice est accompagné d'une indication de niveau de
difficulté:
★★★
Facile
★★★
Difficulté moyenne
★★★
Difficile
Data Mining
Liste de contrôle
Avant de déposer votre projet, vérifiez si vous
respectez
la liste de contrôle suivante:
Les noms complets (prénom et noms) de la binôme sont correctement inclus dans le fichier
CONTRIBUTORS.md.
Le fichier README.md est rempli de manière exhaustive et conforme aux instructions
fournies.
Votre code est accompagné de commentaires appropriés pour expliquer la logique et la
fonctionnalité.
Votre code peut être exécuté sans générer d'erreurs, et dans la mesure du possible, sans
générer d'avertissements.
Le rapport en format PDF (5 pages maximum, Arial 11pt)