Data Mining
John Samuel
CPE Lyon
Année: 2025-2026
Courriel: john.samuel@cpe.fr

John Samuel
CPE Lyon
Année: 2025-2026
Courriel: john.samuel@cpe.fr

Ce processus formalise la transformation des données en informations, puis en connaissances mobilisables pour la décision.

Collecte initiale de données provenant de diverses sources.
La méthode 5W1H (Qui, Quoi, Où, Quand, Pourquoi, Comment) est essentielle pour structurer cette étape : elle permet de définir précisément la source, la nature, le lieu, le moment, la raison et la méthode de collecte des données.



Processus structuré d’intégration qui extrait, transforme et charge les données pour assurer leur qualité, cohérence et disponibilité analytique.

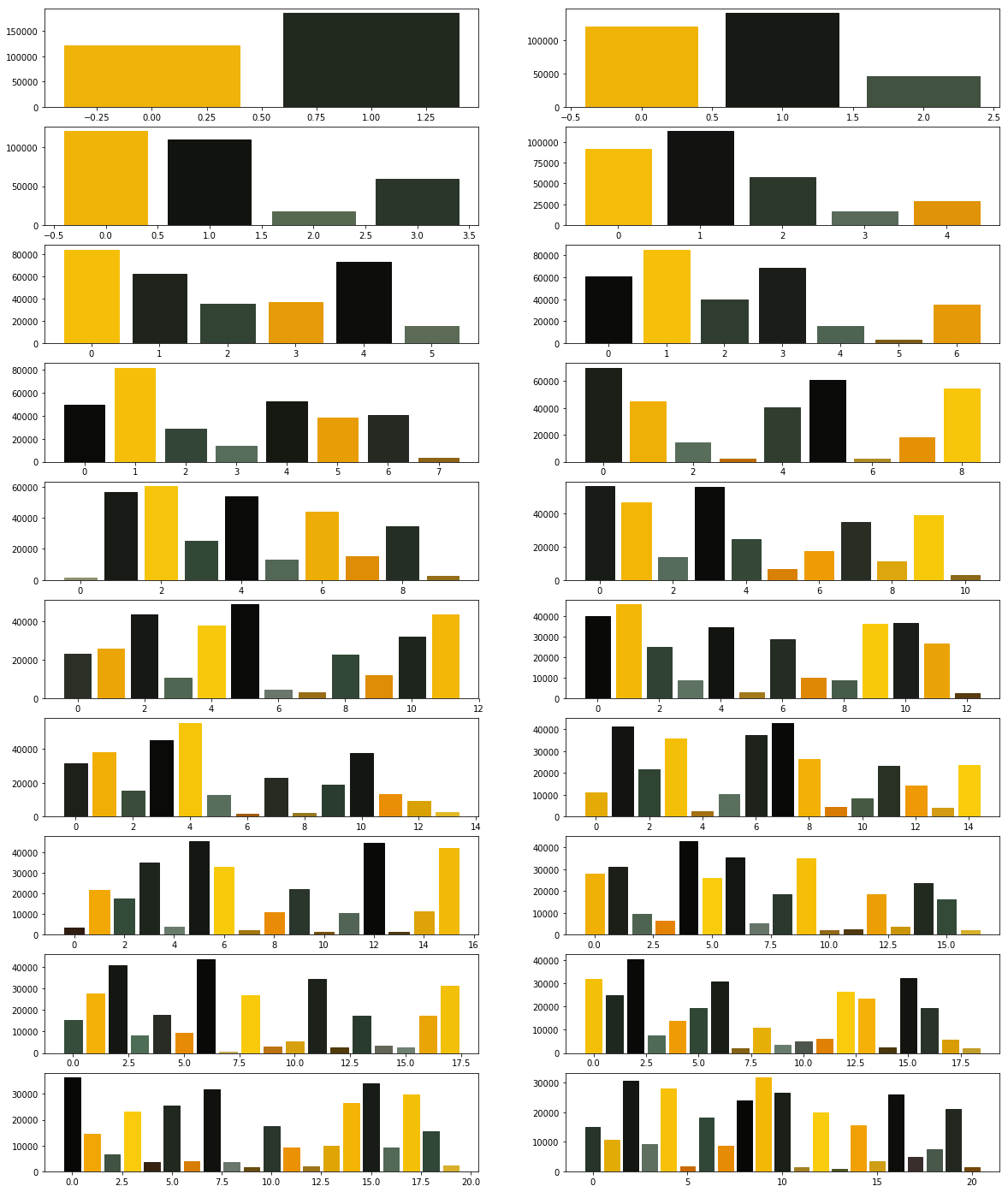
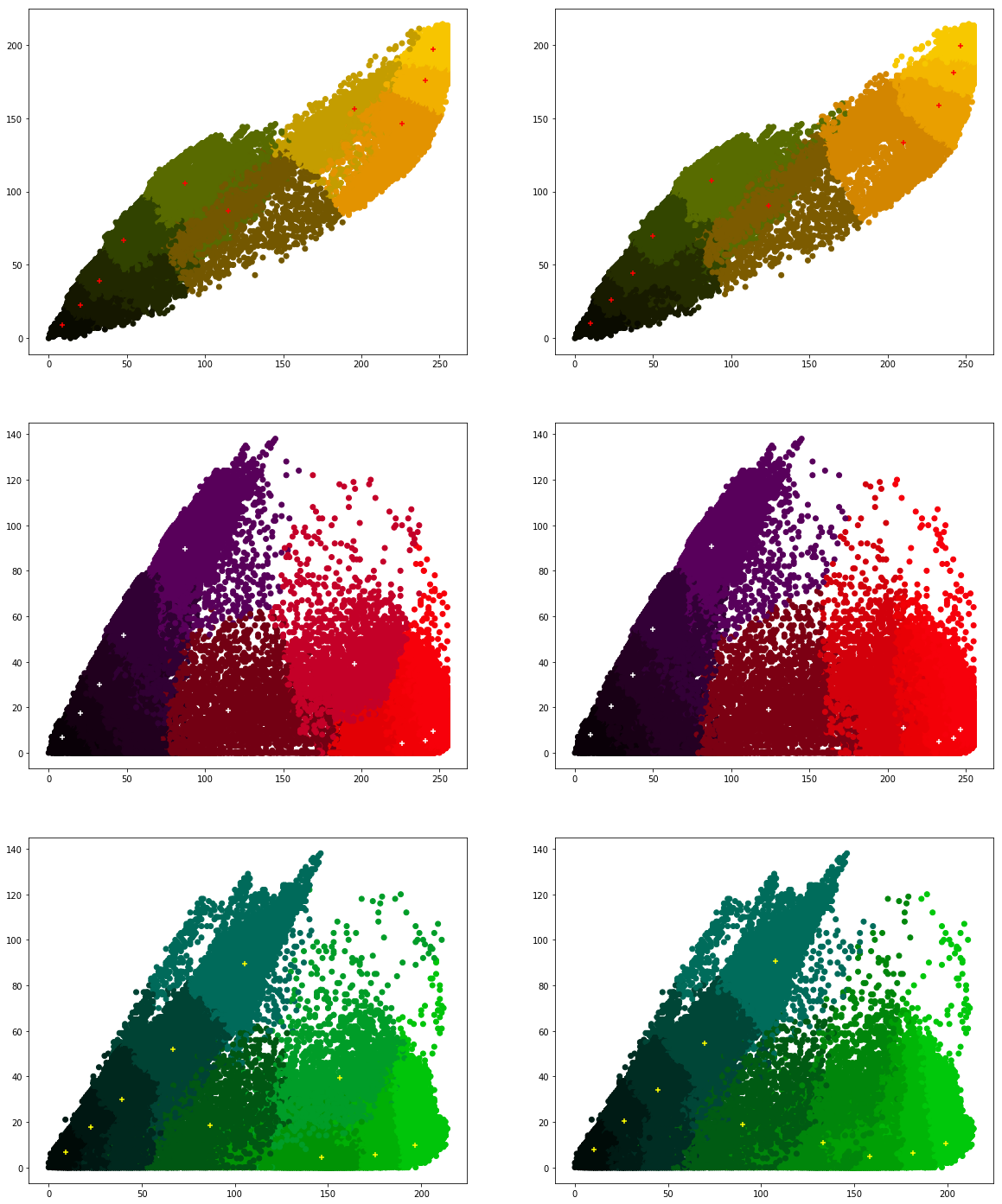
Exploration approfondie des données pour identifier des tendances significatives et des insights pertinents.
Transformation des données en représentations graphiques claires et informatives. Par exemple, graphiques, tableaux de bord, cartes pour faciliter la compréhension visuelle.
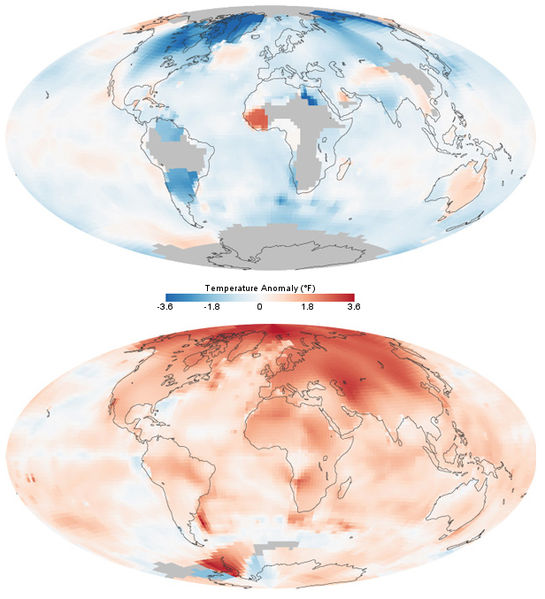
On distingue des données structurées, semi-structurées et non structurées, un cadre qui guide l’organisation, l’accès et les choix de traitement.

.png)
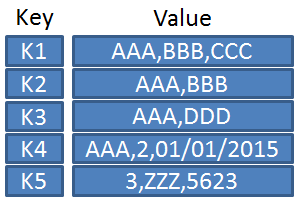
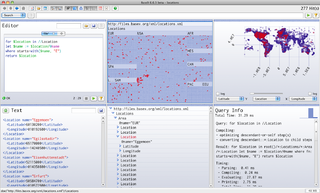
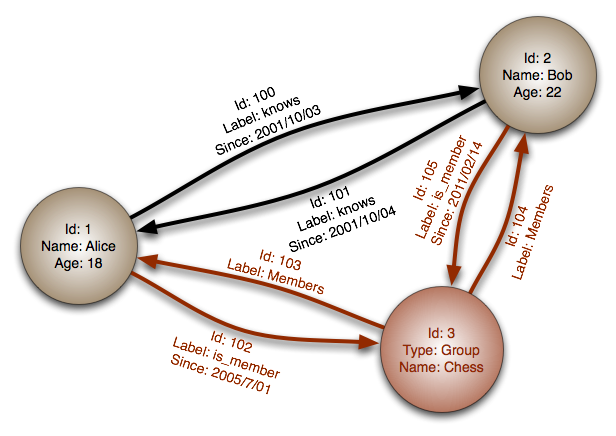
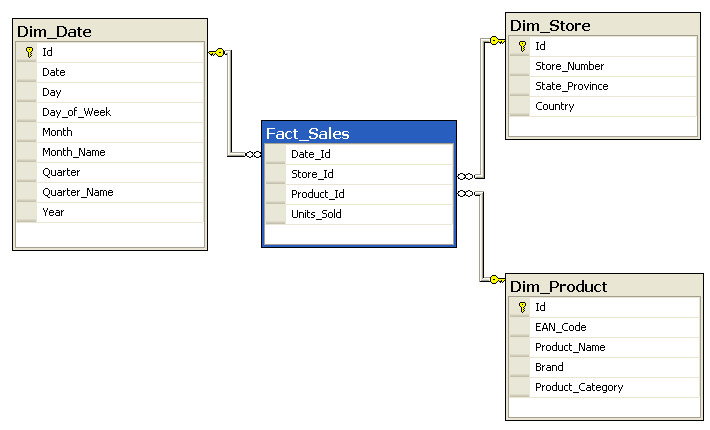
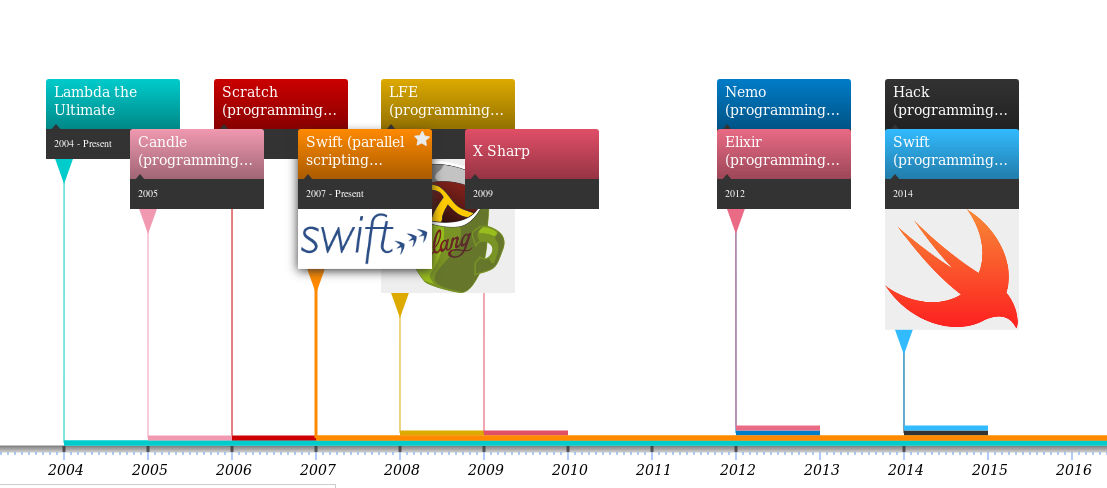
Deux types de nœuds : langage de programmation et année. L’arête year relie un langage à l’année de sa première version.

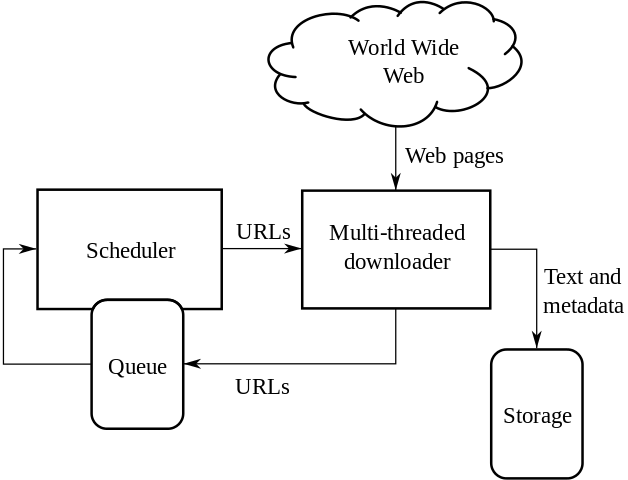
Les crawlers, également appelés robots d'indexation, sont des programmes qui parcourent et analysent automatiquement les pages web pour collecter des informations. Les crawlers naviguent de page en page en suivant les liens, extrayant des données pertinentes telles que le contenu, les liens hypertextes, les balises méta, etc.