Traitement de données massives
John Samuel
CPE Lyon
Année: 2024-2025
Courriel: john.samuel@cpe.fr

John Samuel
CPE Lyon
Année: 2024-2025
Courriel: john.samuel@cpe.fr

$ head /home/john/Downloads/query.csv
itemLabel,year
Amiga E,1993
Embarcadero Delphi,1995
Sather,1990
Microsoft Small Basic,2008
Squeak,1996
AutoIt,1999
Eiffel,1985
Eiffel,1986
Kent Recursive Calculator,1981
$ export HADOOP_HOME="..."
$ ./hive
hive> set hive.metastore.warehouse.dir=${env:HOME}/hive/warehouse;
$./hive
hive> set hive.metastore.warehouse.dir=${env:HOME}/hive/warehouse;
hive> create database mydb;
hive> use mydb;
$./hive
hive> use mydb;
hive> CREATE TABLE IF NOT EXISTS
proglang (name String, year int)
COMMENT "Programming Languages"
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
hive> LOAD DATA LOCAL INPATH '/home/john/Downloads/query.csv'
OVERWRITE INTO TABLE proglang;
$./hive
hive> SELECT * from proglang;
hive> SELECT * from proglang where year > 1980;
$./hive
hive> DELETE from proglang where year=1980;
FAILED: SemanticException [Error 10294]: Attempt to do update
or delete using transaction manager that does not support these operations.
$./hive
hive> use mydb;
hive> CREATE TABLE IF NOT EXISTS
proglangorc (name String, year int)
COMMENT "Programming Languages"
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS ORC;
hive> LOAD DATA LOCAL INPATH '/home/john/Downloads/query.csv'
OVERWRITE INTO TABLE proglangorc;
FAILED: SemanticException Unable to load data to destination table.
Error: The file that you are trying to load does not match
the file format of the destination table.
$./hive
hive> insert overwrite table proglangorc select * from proglang;
hive> DELETE from proglangorc where year=1980;
FAILED: SemanticException [Error 10297]: Attempt to do update
or delete on table mydb.proglangorc that is not transactional
hive> ALTER TABLE proglangorc set TBLPROPERTIES ('transactional'='true') ;
hive> DELETE from proglangorc where year=1980;
hive> SELECT count(*) from proglangorc;
hive> SELECT count(*) from proglangorc where year=1980;
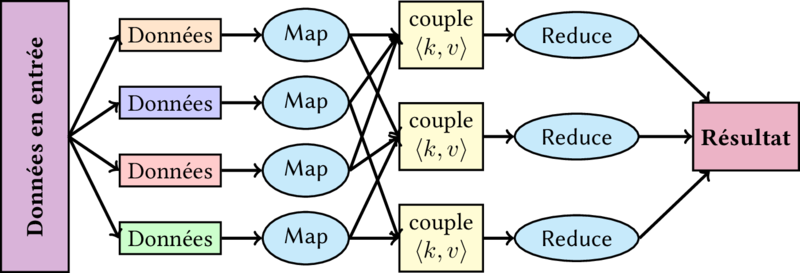
$./pyspark
>>> lines = sc.textFile("/home/john/Downloads/query.csv")
>>> lineLengths = lines.map(lambda s: len(s))
>>> totalLength = lineLengths.reduce(lambda a, b: a + b)
>>> print(totalLength)
$./pyspark
>>> lines = sc.textFile("/home/john/Downloads/query.csv")
>>> lineWordCount = lines.map(lambda s: len(s.split()))
>>> totalWords = lineWordCount.reduce(lambda a, b: a + b)
>>> print(totalWords)
$ export SPARK_HOME='.../spark/spark-x.x.x-bin-hadoopx.x/bin
$ export PYSPARK_PYTHON=/usr/bin/python3
$ export PYSPARK_DRIVER_PYTHON=jupyter
$ export PYSPARK_DRIVER_PYTHON_OPTS='notebook'
$ ./pyspark