Traitement de données massives
John Samuel
CPE Lyon
Année: 2024-2025
Courriel: john.samuel@cpe.fr

John Samuel
CPE Lyon
Année: 2024-2025
Courriel: john.samuel@cpe.fr






.jpg)



.png)



Soit







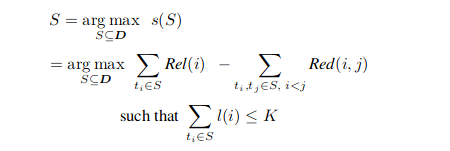
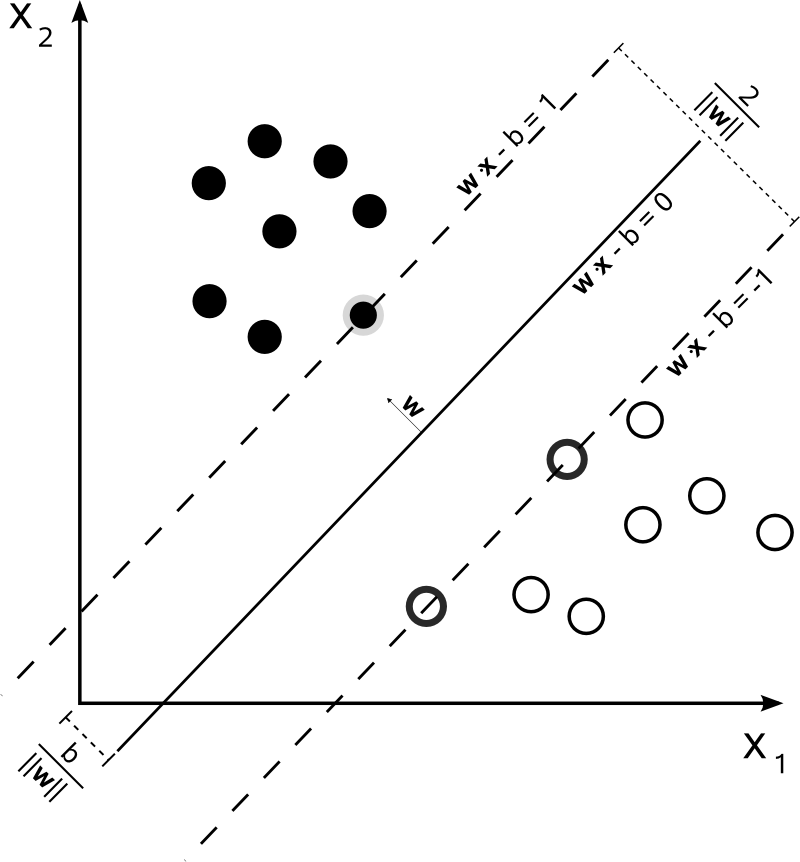
La machine à vecteurs de support (SVM) est une méthode d'apprentissage supervisé. SVM cherche à trouver la meilleure frontière de décision qui optimise la séparation des classes, ce qui permet une classification précise même dans des espaces de données complexes.

L'hyperplan dans l'espace n-dimensionnel est un sous-espace de dimension n-1 qui permet de séparer les données en deux classes.

Le gradient est une généralisation multi-variable de la notion de dérivée.

L'algorithme du gradient stochastique de descente est un algorithme d'optimisation itératif largement utilisé pour trouver le minimum d'une fonction.

L'algorithme stochastique du gradient de descente est une variante où le gradient est calculé de manière stochastique, c'est-à-dire qu'au lieu d'utiliser l'ensemble complet des données pour calculer le gradient à chaque itération, un sous-ensemble aléatoire ou une seule observation est utilisé. Cela permet de gagner en efficacité, en particulier pour les grands ensembles de données.
L'objectif principal de cet algorithme est de minimiser une fonction objective, souvent une fonction de perte dans le cadre de l'apprentissage automatique, et il est largement utilisé dans des domaines tels que l'optimisation convexe, l'apprentissage automatique et le traitement du signal.

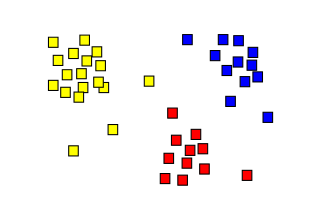
Les "moyens", également appelés centroïdes, sont les points initiaux autour desquels les clusters seront formés. Dans cette étape, k points sont sélectionnés de manière aléatoire à partir de l'ensemble de données pour servir de moyens initiaux.

Dans la deuxième étape de l'algorithme de partitionnement en k-moyennes (k-means clustering), également connue sous le nom d'étape d'affectation, les k clusters sont créés en associant chaque observation à la moyenne la plus proche.Les partitions représentent ici le diagramme de Voronoï généré par les moyennes.

Les centroids de chacun des k agrégats sont recalculés pour devenir les nouvelles moyennes.

La quatrième étape de l'algorithme de partitionnement en k-moyennes (k-means clustering) consiste à répéter les étapes 2 et 3 jusqu'à ce que la convergence soit atteinte.
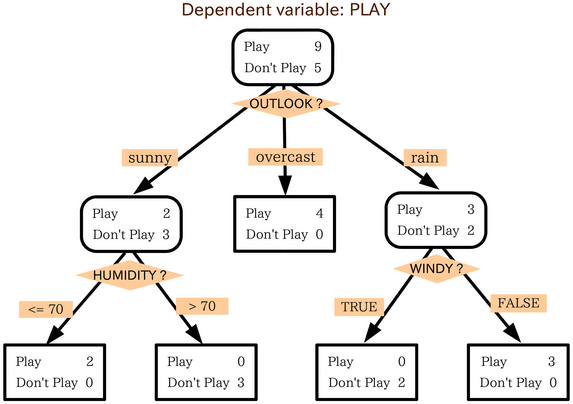
Les arbres de décision sont un outil puissant d'aide à la décision qui utilise un modèle arborescent pour représenter les décisions et leurs conséquences possibles