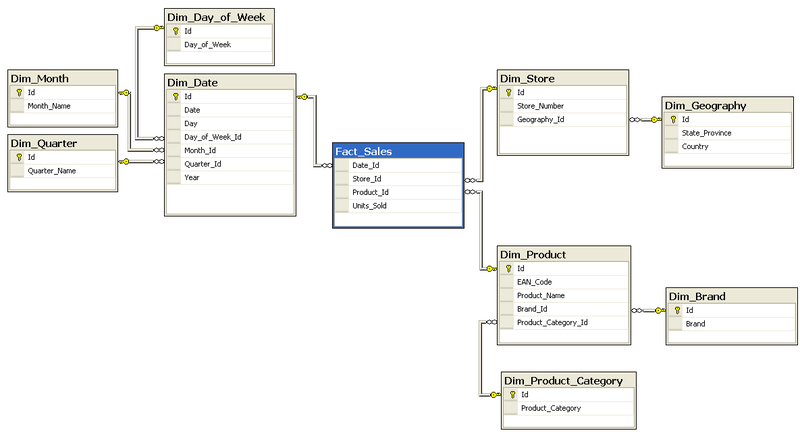
Traitement de données massives
John Samuel
CPE Lyon
Année: 2024-2025
Courriel: john.samuel@cpe.fr

John Samuel
CPE Lyon
Année: 2024-2025
Courriel: john.samuel@cpe.fr


Collecte initiale de données provenant de diverses sources.





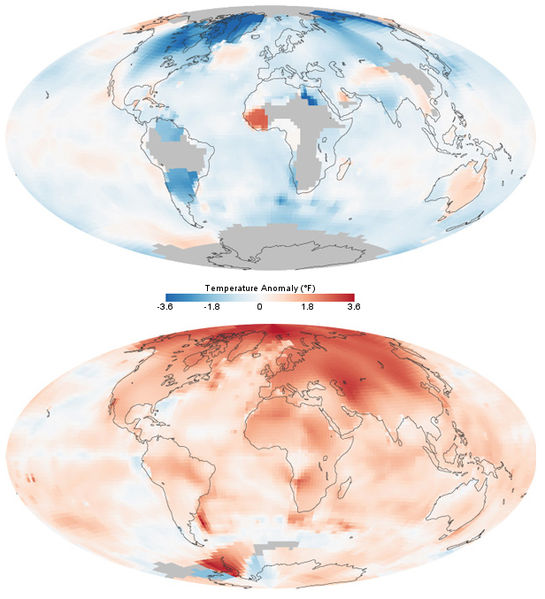
Exploration approfondie des données pour identifier des tendances significatives et des insights pertinents.
Transformation des données en représentations graphiques claires et informatives. Par exemple, graphiques, tableaux de bord, cartes pour faciliter la compréhension visuelle.
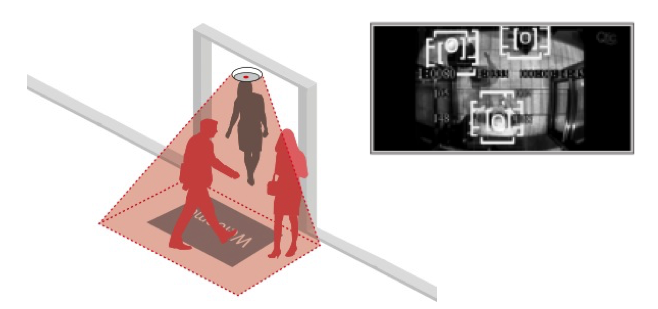
Caissier : Acteur principal dans l'acquisition de données au point de vente.

Acquisition de données dans le domaine de l'e-commerce : Enregistrement des transactions, détails des produits, informations de paiement, et données sur les clients.
Guichet Automatique Bancaire: point d'acquisition de données cruciales dans le secteur financier.

Méthode d'acquisition de données par l'utilisation de capteurs de température.

Méthode d'acquisition de données à travers l'utilisation de caméras vidéo : enregistrement visuel continu de scènes spécifiques.

Acquisition de données à partir des médias et des plateformes de réseaux sociaux : collecte d'informations provenant de publications, commentaires, partages, et interactions en ligne.

Méthode d'acquisition de données impliquant la contribution du grand public : collecte de données provenant d'un grand nombre de participants en ligne. Les données incluent des idées, des avis, des contributions créatives, reflétant la diversité des participants.

Exemple de production participative dans le domaine des données : contributions massives à des projets tels que Wikipédia, Wikibooks, et autres.
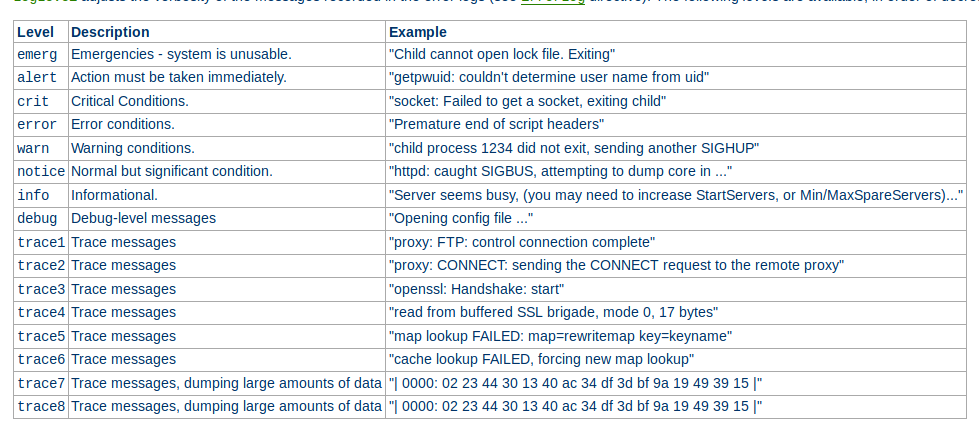
Utilisation de la directive "LogLevel" dans Apache pour définir le niveau de détail des journaux. Paramètre clé influençant la quantité et le type de données enregistrées.
Personnalisation du format pour inclure des informations spécifiques dans les enregistrements.
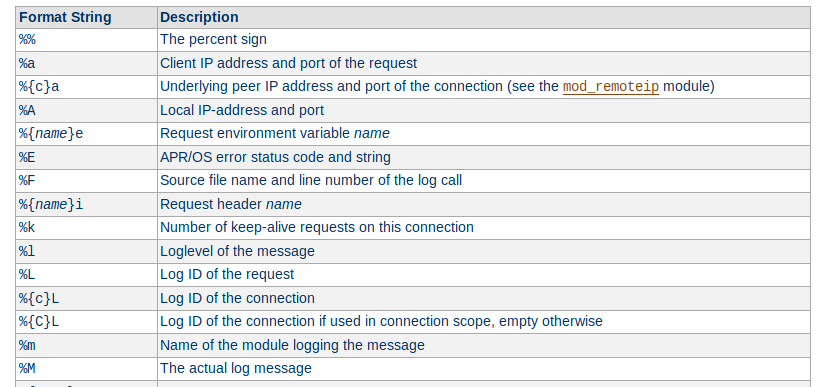


.png)
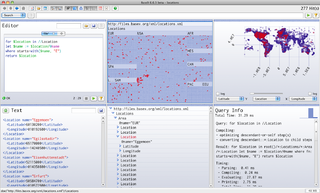
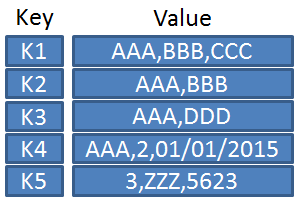
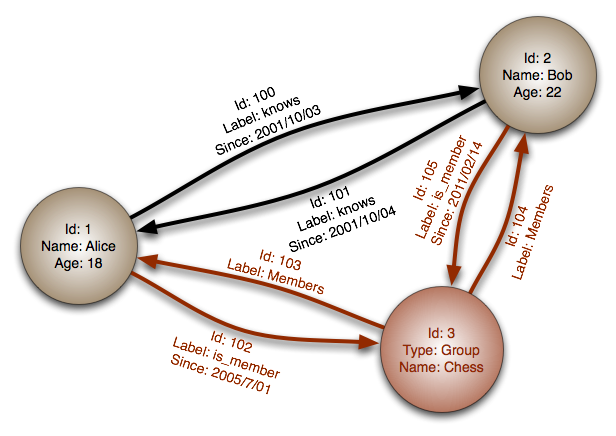

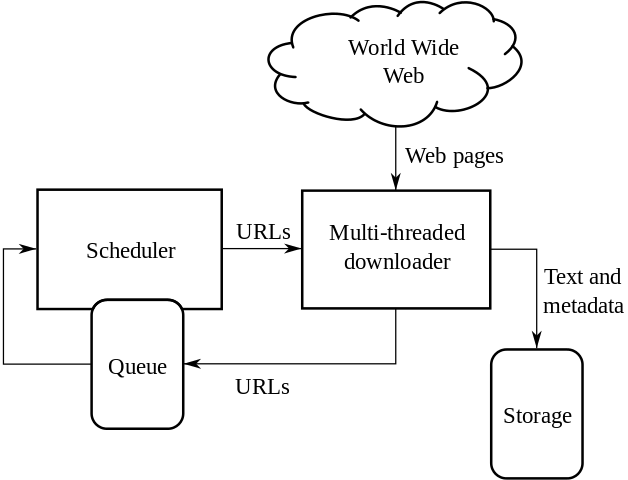
Les crawlers, également appelés robots d'indexation, sont des programmes qui parcourent et analysent automatiquement les pages web pour collecter des informations. Les crawlers naviguent de page en page en suivant les liens, extrayant des données pertinentes telles que le contenu, les liens hypertextes, les balises méta, etc.