Principes des Langages de programmation
John Samuel
CPE Lyon
Année: 2024-2025
Courriel: john.samuel@cpe.fr

CPE Lyon
Année: 2024-2025
Courriel: john.samuel@cpe.fr

Un langage de programmation est un ensemble de règles, de syntaxe et de sémantique utilisés pour communiquer des instructions à un ordinateur. Il permet aux développeurs d’écrire du code qui peut être exécuté par l’ordinateur, réalisant ainsi des tâches spécifiques ou résolvant des problèmes.
Composants clés :
Composants clés :
Caractéristiques :
L'émergence de modèles d'intelligence artificielle multilingues marque un jalon important dans l'évolution de la programmation. À mesure que ces modèles élargissent leurs capacités linguistiques, ils nous rapprochent d'un monde où chacun peut communiquer avec les machines dans sa langue maternelle.
The hottest new programming language is English. Andrej Karpathy, jan 24, 2023.
Human Languages as New Hot Programming Languages. J.S., October 4, 2023.
L'indice TIOBE de la communauté de programmation, mis à jour une fois par mois, est un indicateur de la popularité des langages de programmation.
Les langages de programmation les plus populaires sur GitHub (2023):
Voici la classification des langages de programmation en fonction de leur utilisation principale :
Développement Web
Développement d’Applications Mobiles
Administration Système
Applications de Bureau
Développement de Jeux
Calcul Scientifique
Scripting
1. Programmation Fonctionnelle
Exemples : Haskell, Lisp, Scheme
2. Programmation Orientée Objet (POO)
Exemples : Java, C++, Python, Ruby
3. Programmation Impérative
Exemples : C, Fortran, Langages assembleur
4. Programmation Déclarative
5. Programmation Orientée Aspect (POA)
Exemples : AspectJ, Java AOP
6. Langages Spécifiques à un Domaine (DSL)
7. Programmation Pilotée par Événements
Exemples : JavaScript, Node.js, React
8. Développement Piloté par les Types (TDD)
8. Développement Piloté par les Types (TDD)
9. programmation basée sur les propriétés
Tendances émergentes :
Le langage C est un langage de programmation :
Remarque: Pas de classes (Ce n'est pas un langage de programmation orienté-objet!!!)
Extensions de fichiers : .c, .h
| Caractéristique | Langage C | Python |
|---|---|---|
| Paradigme de programmation | Impératif, procédural | Multiparadigme (impératif, orienté objet, fonctionnel) |
| Typage | Statique (typage fort) | Dynamique (typage fort) / Statique (Python 3.5+) |
| Syntaxe | Syntaxe stricte et rigide | Syntaxe simple et lisible |
| Performance | Performant, optimisé pour les performances | Moins performant, interprété |
| Gestion de la mémoire | Besoin de gérer manuellement la mémoire | Gestion automatique de la mémoire (ramassage des ordures) |
| Portabilité | Portable, mais nécessite une compilation spécifique pour chaque plateforme | Hautement portable grâce à son interpréteur |
/* Fichier: bonjour1.c
* affiche 'Bonjour le Monde!!!' à l'écran.
* auteur: John Samuel
* Ceci est un commentaire sur plusieurs lignes
*/
#include
<stdio.h> // headers
// Ceci est un commentaire
sur une ligne
int main()
{
printf("Bonjour le Monde
!!!");
return
0;
}
Objectif : Ce code utilise des commentaires, inclut le fichier d'en-tête <stdio.h> pour l'utilisation de printf, définit la fonction main comme point d'entrée, utilise printf pour afficher un message, et renvoie 0 pour indiquer une exécution sans erreur.
/* Fichier: bonjour2.c
* affiche un message à l'écran en utilisant une variable
* auteur: John Samuel
* Ceci est un commentaire
sur plusieurs lignes
*/
#include <stdio.h> // headers
int main()
{
int annee = 2024;
//déclaration d'une variable
printf("Bonjour le Monde!!! C'est l'annee %d", annee);
return 0;
}
Objectif : Ce code déclare une variable annee, utilise printf pour afficher un message incluant la valeur.
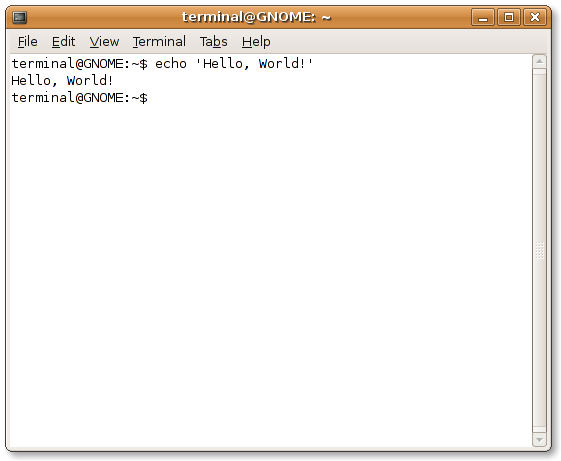
$ gcc bonjour1.c
Pour voir tous les avertissements (*warnings*) pendant la compilation, vous pouvez utiliser les options -Wall et -Wextra.
$ gcc -Wall -Wextra -o bonjour bonjour.c
$./a.out
Bonjour le Monde!!!
$ gcc -o bonjour bonjour2.c
$./bonjour
Bonjour le Monde!!! C'est l'annee 2024
# Ce programme affiche le message "Bonjour le monde !!!" à l'écran
# Définition de la fonction principale
def main():
# Affichage du message
print("Bonjour le monde !!!")
# Vérification si le script est exécuté directement (et non importé comme module)
if __name__ == "__main__":
# Appel de la fonction principale
main()
$ python3 bonjour.py
Bonjour le monde!!!
// Ceci est un commentaire sur une ligne (c99)
/* Ceci est un
* commentaire sur
* quatre lignes
*/
# Ceci est un commentaire sur une ligne
""" Ceci est un
* commentaire sur
* quatre lignes
"""
Les types de base en C sont les fondations sur lesquelles sont construites toutes les variables et données dans ce langage de programmation.
| Types | Mots clés | Exemples |
|---|---|---|
| caractères | char | 'h', 'a', ... |
| entiers | short, int, long, long long | ...,-1,0,1,... |
| nombres en flottant | float, double, long double | 3.14, 3.14e23 |
| énumrérations | enum | ETUDIANT, STAGIAIRE |
Le choix de stocker des données en un octet, deux octets, quatre octets ou huit octets dépend principalement de la précision nécessaire pour représenter les données.

| Types | Mots-clés |
|---|---|
| caractère | signed char, unsigned char |
| entier | signed short, signed int, signed long, signed long long, unsigned short, unsigned int, unsigned long, unsigned long long |
Remarque : La taille des types de base en C n'est pas standardisée car elle dépend de l'architecture matérielle sous-jacente du système sur lequel le code est exécuté, ce qui permet d'optimiser l'utilisation de la mémoire et les performances pour chaque plate-forme.
L'intervalle minimum et maximum de types de base en utilisant limits.h
| Mots clés | Intervalle |
|---|---|
| signed char | [SCHAR_MIN, SCHAR_MAX] |
| unsigned char | [0, UCHAR_MAX] |
| Mots clés | Intervalle |
|---|---|
| (signed) short int | [SHRT_MIN, SHRT_MAX] |
| unsigned short int | [0, USHRT_MAX] |
| (signed) int | [INT_MIN, INT_MAX] |
| unsigned int | [0, UINT_MAX] |
| (signed) long | [LONG_MIN, LONG_MAX] |
| unsigned long | [0, ULONG_MAX] |
| (signed) long long | [LLONG_MIN, LLONG_MAX] |
| unsigned long long | [0, ULLONG_MAX] |
L'intervalle minimum et maximum de types flottant en utilisant float.h
| Mots clés | Intervalle |
|---|---|
| float | [FLT_MIN, FLT_MAX] |
| double | [DBL_MIN, DBL_MAX] |
| long double | [LDBL_MIN, LDBL_MAX] |
Les principaux types de données en Python :
Entiers (int) : Les entiers sont des nombres entiers sans partie décimale. Par exemple : 1, 2, 3, etc.
Flottants (float) : Les flottants sont des nombres à virgule flottante, c’est-à-dire des nombres avec une partie décimale. Par exemple : 3.14, -0.5, etc.
Chaînes de caractères (str) : Les chaînes de caractères sont des séquences de caractères, telles que des mots ou des phrases. Elles sont délimitées par des guillemets simples ou doubles. Par exemple : “Bonjour”, ‘Bonjour’, etc.
Booléens (bool) : Les booléens sont des valeurs logiques qui peuvent être soit True (vrai), soit False (faux).
Listes (list) : Les listes sont des collections ordonnées de valeurs qui peuvent être de n’importe quel type, y compris des listes imbriquées. Elles sont délimitées par des crochets et les éléments sont séparés par des virgules. Par exemple : [1, 2, 3], [“a”, “b”, “c”], etc.
Tuples (tuple) : Les tuples sont des collections ordonnées de valeurs qui peuvent être de n’importe quel type, y compris des tuples imbriqués. Ils sont délimités par des parenthèses et les éléments sont séparés par des virgules. Par exemple : (1, 2, 3), (“a”, “b”, “c”), etc.
Dictionnaires (dict) : Les dictionnaires sont des collections non ordonnées de paires clé-valeur. Les clés sont uniques et les valeurs peuvent être de n’importe quel type. Les dictionnaires sont délimités par des accolades et les paires clé-valeur sont séparées par des virgules. Par exemple : {“nom”: “Jean”, “âge”: 30}, etc.
Ensembles (set) : Les ensembles sont des collections non ordonnées d’éléments uniques. Ils sont délimités par des accolades et les éléments sont séparés par des virgules. Par exemple : {1, 2, 3}, {“a”, “b”, “c”}, etc.
Nombres complexes (complex) : Les nombres complexes sont des nombres qui ont une partie réelle et une partie imaginaire. Par exemple : 3 + 4j, -2 - 5j, etc.
Les variables de type "char" en C sont utilisées pour stocker des caractères, mais elles peuvent également être modifiées avec les qualificateurs "signed" (signé) ou "unsigned" (non signé) pour déterminer si elles peuvent représenter des valeurs négatives (signées) ou uniquement des valeurs positives (non signées).
char my_char_var1 = 'a';
char my_char_var2 = -125;
unsigned char my_char_var3 = 225;
Remarque: Remarquez-bien l'utilisation de sous-tiret en nommant les variables

char my_char_var = 'a';
unsigned char my_uchar_var = 234;
short my_short_var = -12;
unsigned short my_ushort_var = 65535;
int my_int_var = 12;
unsigned int my_uint_var = 3456;
long my_long_var = -1234553L;
unsigned long my_ulong_var = 234556UL;
long long my_llong_var = 1123345LL;
unsigned long long my_ullong_var = 1234567ULL;
float my_float_var = 3.14;
double my_double_var = 3.14E-12;
long double my_long_double_var = 3.14E-22;
Les énumérations en C sont un moyen de définir un nouveau type de données personnalisé pour représenter un ensemble fini de valeurs entières nommées. Elles sont utiles pour rendre le code plus lisible et compréhensible.
enum status {ETUDIANT, STAGIAIRE}; // ETUDIANT = 0, STAGIAIRE = 1
enum status s = ETUDIANT;
enum status {ETUDIANT=1, STAGIAIRE}; // STAGIAIRE = 2
enum status {ETUDIANT=1, STAGIAIRE=14, ENSEIGNANT}; // ENSEIGNANT = 15
enum boolean {FAUX=0, VRAI};
Remarque: enum: unsigned int
sizeof (char) //type
sizeof (my_uchar_var) //variable
printf("sizeof(char): %lu\n",
sizeof (char));
printf("sizeof(long long int): %lu\n",
sizeof (long long int));
printf("sizeof(my_char_var): %lu\n",
sizeof (my_char_var));
Remarque 1: sizeof donne la taille d'une variable en octets ou d'un type de données.
Remarque 2: La valeur retournée peut varier, mais la taille d'une variable de type caractère est de 1 octet.
Remarque 3: La valeur retournée est du type "unsigned long int". C'est pourquoi nous utilisons "%lu".
L'objectif de la fonction sys.getsizeof() en Python est de retourner la taille en octets
d'un objet spécifique. Cette fonction est utile pour connaître la taille mémoire d'un objet, ce qui peut
être utile pour l'optimisation de la mémoire ou pour comprendre comment les objets sont stockés en
mémoire.
sys.getsizeof() prend en compte la taille de l'objet lui-même, ainsi que la
taille de tous les objets qu'il référence. Cela signifie que si vous utilisez sys.getsizeof() sur un
objet qui contient d'autres objets, la fonction retournera la taille totale de l'objet et de tous
les objets qu'il référence.sys.getsizeof() ne prend pas en compte la taille des
objets qui sont référencés par les objets qu'il mesure. Par exemple, si vous avez une liste qui
contient des objets qui référencent d'autres objets, sys.getsizeof() ne prendra pas en compte la
taille de ces objets référencés.import sys
i = 10
f = 3.14159
s = "Bonjour"
# Affiche la taille en octets (varie en fonction de la plateforme)
print("Taille (int): ", sys.getsizeof(i)) # 28
print("Taille (float): ", sys.getsizeof(f)) # 24
print("Taille (str): ", sys.getsizeof(s)) # 56
len() est une fonction intégrée à Python qui retourne le nombre d'éléments dans un objet
séquentiel, tel qu'une liste, un tuple, une chaîne de caractères, etc. Elle compte le nombre d'éléments
dans l'objet, mais ne prend pas en compte la taille mémoire de l'objet lui-même.
import sys
# Création d'une liste avec 10 entiers
ma_liste = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Obtenir la longueur de la liste
longueur_liste = len(ma_liste)
print(longueur_liste) # Affiche 10
# Obtenir la taille de la liste
taille_liste = sys.getsizeof(ma_liste)
print(taille_liste) # Affiche la taille de la liste en octets (varie en fonction de la plateforme)
Les tableaux sont des structures de données permettant de stocker un ensemble de valeurs du même type sous un même nom, organisées de manière séquentielle.

Les tableaux à deux indices sont des structures de données qui permettent de stocker des données dans une matrice rectangulaire.
Les tableaux à deux indices sont utiles pour stocker des données tabulaires, des images, des matrices, etc.

Les tableaux à plusieurs indices sont des structures de données permettant de stocker des données dans des dimensions multiples.
Les tableaux à plusieurs indices sont utilisés pour stocker des données tridimensionnelles, telles que des voxels dans une image 3D, des matrices 3D, des jeux de données multidimensionnels, etc.

Pour déclarer un tableau, spécifiez le type des éléments qu'il contiendra, suivi du nom du tableau et de sa taille entre crochets.
par exemple
int tableau[5];
déclare un tableau d'entiers de taille 5.
char nom[20];
déclare un tableau de caractères (ou une chaîne de caractères) de taille 20.
Remarque: Langage C n'a pas un type nommé 'string'.
Les tableaux ont une taille fixe à la déclaration, qui ne peut pas être modifiée pendant l'exécution.
Exemple :
int itableau[20];
float ftableau[20];
double dtableau[20];
Objectif :
Exemple :
int i;
int tableau[20];
for ( i = 0;
i < 20; i++) {
tableau[i] =
i;
}
Exemple :
int prix[5] = {
11, 12, 13, 14, 15 };
int chambres[] = {
301, 302, 303 };
char message[] = "Bonjour Le Monde!!";
Remarque: Nous n'avons pas écrit la taille de chambres, message
Exemple :
int prix[5] = {
11, 12, 13, 14, 15 };
sizeof (prix) // 5 * sizeof(int)
Exemple :
int chambres[] = {
301, 302, 303 };
sizeof (chambres) // 3 * sizeof(int)
Exemple :
char message[] = "Bonjour Le Monde!!";
sizeof (message) // (18 + 1 (NULL)) * sizeof(char)
int prix[2][2] = {
{11, 12},
{13, 14}
};
sizeof (prix) // 2 * 2 * sizeof(int)
int chambres[][2] = {
{201, 202},
{301, 302}
};
sizeof (chambres) // 2 * 2 * sizeof(int)
Remarque: Nous n'avons pas précisé le nombre de lignes pour chambres.
char message[2][11] =
{"Bonjour", "Le Monde!!"};
sizeof (message) // 2 * 11 * sizeof(char)
printf("%d",
my_int_var);
printf("%f",
my_float_var);
| Mots clés | Code de conversion |
|---|---|
| char | c |
| unsigned char | hhu |
| short | hd |
| unsigned short | hu |
| int | d, i |
| unsigned int | u |
| long int | ld |
| unsigned long int | lu |
| Mots clés | Code de conversion |
|---|---|
| long long int | lld |
| unsigned long long int | llu |
| float | f, F,e, E |
| double | g, G |
| long double | Lg, LG, Le, LE |
| string of characters | s |
| Character | Code de conversion |
|---|---|
| Retour-chariot | \n |
| Tabulation | \t |
/* Fichier: addition.c
* affichage de la somme des nombres
* saisis par l'utilisateur */
#include
<stdio.h> // en-têtes(headers)
int main(int argc, char ** argv)
{
int num1, num2;
printf("Tapez numéro 1");
scanf("%d", &num1);
printf("Tapez numéro 2");
scanf("%d", &num2);
printf("La somme: %d\n", num1 + num2);
return 0;
}
L'objectif de la fonction scanf est de permettre à un programme de lire et de stocker des données à partir de l'entrée standard (généralement le clavier) ou d'autres flux d'entrée, en fonction d'un format spécifié.
Remarque: Regardez l'opérateur &.
/* Fichier: addition.c
* affiche la somme de deux numéros
* saisis par l'utilisateur
* auteur: John Samuel
*/
#include
<stdio.h> // en-têtes(headers)
int main(int argc, char ** argv)
{
int num1, num2;
printf("Tapez deux numéros: ");
scanf("%d %d", &num1, &num2);
printf("La somme: %d\n", num1 + num2);
return 0;
}
Remarque: Regardez l'opérateur &. L'opérateur & est utilisé pour obtenir l'adresse mémoire des variables num1 et num2, de sorte que les valeurs entrées par l'utilisateur puissent être stockées à ces emplacements en mémoire.
/* Fichier: bonjour5.c
* affiche un message à l'écran en utilisant scanf.
* auteur: John Samuel
*/
#include
<stdio.h> // en-têtes(headers)
int main(int argc, char ** argv)
{
char nom[50];
printf("Bonjour. Votre nom? ");
scanf("%s", nom);
printf("Bonjour %s!", nom);
return 0;
}
Remarque: Regardez nom sans l'opérateur &. Lorsque vous utilisez la fonction scanf pour lire une chaîne de caractères à l'aide du format "%s", vous n'avez pas besoin d'inclure le symbole & devant la variable nom. La raison en est que nom est déjà un pointeur vers un tableau de caractères (c'est-à-dire un pointeur vers la première case mémoire du tableau), et scanf s'attend à recevoir l'adresse de la mémoire où stocker la chaîne de caractères. Par conséquent, nom en tant que pointeur fournit cette adresse.
| Mots clés | Code de conversion |
|---|---|
| char | c |
| unsigned char | hhu |
| short | hd |
| unsigned short | hu |
| int | d, i |
| unsigned int | u |
| long int | ld |
| unsigned long int | lu |
| Mots clés | Code de conversion |
|---|---|
| long long int | lld |
| unsigned long long int | llu |
| float | f, F |
| double | g, G |
| long double | Lg |
| string of characters | s |
/* Fichier: fgets-message.c
* affichage d'une phrase entrée par un utilisateur
* la phrase peut contenir un espace
* auteur: John Samuel
*/
#include
<stdio.h> // en-têtes(headers)
int main(int argc, char ** argv)
{
char message[50];
printf("Tapez votre message: ");
fgets(message, sizeof(message), stdin);
printf("Votre message: %s\n", message);
return 0;
}
Remarque: Regardez le paramètre stdin.La fonction fgets est utilisée pour lire une ligne de texte depuis l'entrée standard ( stdin) et stocker cette ligne dans la variable message. La taille du tampon de destination ( message) est spécifiée par sizeof(message), ce qui permet de garantir que la fonction ne lira pas plus de caractères que ce que le tampon peut contenir, évitant ainsi les dépassements de mémoire.
Unicode est un standard qui définit une manière unique de représenter les caractères de toutes les langues du monde. Il attribue un code unique à chaque caractère, appelé “point de code” ou “codepoint”. Unicode est utilisé pour représenter les caractères dans les ordinateurs, les téléphones et les autres appareils électroniques.
UTF-8 (Unicode Transformation Format 8) est un encodage de caractères qui utilise une séquence variable de 1 à 4 octets pour représenter chaque caractère Unicode. UTF-8 est l’encodage le plus couramment utilisé pour les caractères sur Internet et est pris en charge par la plupart des systèmes d’exploitation et des langages de programmation.
Voici comment UTF-8 fonctionne :
UTF-16 (Unicode Transformation Format 16) est un encodage de caractères qui utilise 2 octets pour représenter chaque caractère Unicode. UTF-16 est utilisé par les systèmes d’exploitation Windows et est pris en charge par de nombreux langages de programmation.
Voici comment UTF-16 fonctionne :
Voici comment UTF-16 fonctionne :
UTF-32 (Unicode Transformation Format 32) est un encodage de caractères qui utilise 4 octets pour représenter chaque caractère Unicode. UTF-32 est utilisé dans certains systèmes d’exploitation et est pris en charge par certains langages de programmation.
Voici comment UTF-32 fonctionne :
L’encodage et le décodage sont des processus qui permettent de convertir des données entre différents formats. Dans le contexte des caractères, l’encodage consiste à convertir des caractères en une séquence de bits (0 et 1) qui peuvent être stockés ou transmis par un ordinateur. Le décodage est l’opération inverse, qui consiste à convertir une séquence de bits en caractères.
UTF-8 est l’encodage le plus couramment utilisé pour les caractères sur Internet, UTF-16 est utilisé par les systèmes d’exploitation Windows, et UTF-32 est utilisé dans certains systèmes d’exploitation et langages de programmation.
Les opérateurs arithmétiques en C sont des symboles spéciaux tels que "+", "-", "*", "/", et "%" utilisés pour effectuer des opérations mathématiques telles que l'addition, la soustraction, la multiplication, la division et le modulo sur des valeurs numériques, facilitant ainsi la manipulation des données numériques dans les programmes.
| Opérateur | Objectif |
|---|---|
| + | addition |
| - | soustraction |
| * | multiplication |
| / | division |
| % | modulus |
int
a = 20,
b = 10;
| Opérateur | Exemple | Résultat |
|---|---|---|
| + | a + b | 30 |
| - | a - b | 10 |
| * | a * b | 200 |
| / | a / b | 2 |
| % | a % b | 0 |
Les opérateurs relationnels en C, tels que "==", "!=", "<", ">" , "<=" , et ">=" , sont utilisés pour comparer des valeurs numériques ou des expressions et renvoient une valeur booléenne (vrai ou faux) en fonction de la relation spécifiée, ce qui permet de prendre des décisions conditionnelles dans les programmes en évaluant des conditions.
| Opérateur | Objectif |
|---|---|
| < | inférieur |
| <= | inférieur ou égale |
| > | supérieur |
| >= | supérieur ou égale |
| == | égale |
| != | différent |
int
a = 20,
b = 10;
| Opérateur | Exemple | Résultat |
|---|---|---|
| < | a < b | 0 |
| <= | a <= b | 0 |
| > | a > b | 1 |
| >= | a >= b | 1 |
| == | a == b | 0 |
| != | a != b | 1 |
Remarque: Une valeur différente de zéro est considérée comme VRAIE et la valeur zéro est considérée comme FAUSSE.
Les opérateurs logiques en C, tels que "&&" (ET logique), "||" (OU logique) et "!" (NON logique), sont utilisés pour combiner des expressions booléennes et effectuer des opérations de logique booléenne, ce qui permet de prendre des décisions conditionnelles complexes en évaluant plusieurs conditions simultanément dans les programmes.
int
a = 20,
b = 0;
| Opérateur | Objectif | Exemple | Résultat |
|---|---|---|---|
| ! | Négation | !a | 0 |
| && | Et | a && b | 0 |
| || | Ou | a || b | 1 |
Remarque: Une valeur différente de zéro est considérée comme VRAIE et la valeur zéro est considérée comme FAUSSE.
Les opérateurs d'incrémentation en C, "++" (incrémentation) et "--" (décrémentation), sont utilisés pour augmenter ou diminuer la valeur d'une variable numérique de 1, ce qui facilite les itérations et les mises à jour de variables dans les boucles et les calculs.
int
a = 20,
b = 0;
| Opérateur | Exemple | Résultat |
|---|---|---|
| a++ | b = a++ | a = 21, b = 20 |
| ++a | b = ++a | a = 21, b = 21 |
| a-- | b = a-- | a = 19, b = 20 |
| --a | b = --a | a = 19, b = 19 |
Les opérateurs de manipulation de bits en C, tels que "&" (ET bit à bit), "|" (OU bit à bit), "^" (OU exclusif bit à bit) et "~" (NON bit à bit), permettent de réaliser des opérations de manipulation au niveau des bits au sein des données binaires, ce qui est utile pour effectuer des opérations de masquage, de décalage et de gestion de bits individuels dans les programmes.
| Bit 1 | Bit 2 | & | | | ^ (XOR) |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
Remarque: Les valeurs ci-dessus (0 et 1) sont des bits binaires et non des valeurs entières.
int
a = 0b01000100;
| Opérateur | Objectif | Exemple | Résultat |
|---|---|---|---|
| ~ | Négation | ~a | 0xffffffbb |
| & | ET | a & 0x4 | 0x4 |
| | | OR | a | 0x2 | 0x46 |
| ^ | XOR | a ^ 0x4 | 0x40 |
| << | décalage à gauche | a << 1 | 0x88 |
| >> | décalage à droite | a >> 1 | 0x22 |
Les opérateurs d'affectation de bits en C, tels que "&=", "|=", "^=", "<<=", et ">>=" , sont utilisés pour combiner des opérations de manipulation de bits avec une opération d'affectation. Ils permettent de modifier les valeurs d'une variable en fonction du résultat d'une opération de manipulation de bits, ce qui simplifie la gestion des données au niveau des bits. Remarque: a op = b ::- a = a op b
| Opérateur | Objectif | Exemple |
|---|---|---|
| = | equal | a = b |
| += | addition | a += b |
| -= | substraction | a -= b |
| *= | multiplication | a *= b |
| /= | division | a /= b |
| %= | modulo | a %= b |
| Opérateur | Objectif | Exemple |
|---|---|---|
| &= | ET | a &= b |
| |= | OU | a |= b |
| ^= | XOR | a ^= b |
| <<= | décalage à gauche | a <<= b |
| >>= | décalage à droite | a >>= b |
Remarque: a op = b ::- a = a op b
if (condition) {
...
}

int
a = 20,
b = 0;
if (a >
b) {
printf("a est supérieur à b");
}
L'objectif est de vérifier si la valeur de a est supérieure à celle de b et d'afficher un message si la condition est vraie.
Les instructions if...else if...else permettent d'exécuter un bloc de code en fonction de plusieurs conditions alternatives.
if (condition1) {
...
} else if (condition2) {
...
} else {
...
}
Les instructions if...else if...else permettent d'exécuter un bloc de code en fonction de plusieurs conditions alternatives.
if (condition1) {
...
} else if (condition2) {
...
} else {
...
}
int
a = 20,
b = 0;
if (a >
b) {
printf("a est supérieur à b");
} else if (a <
b) {
printf("a est inférieur à b");
} else {
printf("a égale b");
}

switch est utilisée pour sélectionner une action à exécuter en fonction de la valeur de l'expression fournie.
switch (expression) {
case valeur1 : instructions1
case valeur2 : instructions2
...
default : instructionsn
}
switch (expression) {
case valeur1 : instructions1
case valeur2 : instructions2
...
default : instructionsn
}
int
a = 20;
switch (a) {
case 10 : instructions1
break;
case 20 : instructions2
case 30 : instructions3
break;
...
default : instructionsn
}
Remarque:Le code exécute instructions2 et continue à exécuter instructions3 car il n'y a pas de break après instructions3.
if (1) {
printf("Hi");
} else {
printf("Bonjour");
}
for(initialisation;condition;actualisation){
...
}
L'objectif de la boucle for en programmation est de répéter un bloc de code un certain nombre de fois en suivant les étapes suivantes
Ces étapes permettent de créer des boucles flexibles qui peuvent être utilisées pour parcourir des éléments d'une liste, effectuer des calculs répétitifs, ou exécuter des actions itératives. La boucle for est couramment utilisée pour simplifier la gestion des itérations dans un programme.
for(initialisation;condition;actualisation){
...
}

int
a = 0;
for( a = 0;
a < 10;
a++){
...
}
L'objectif de ce code est d'initialiser la variable a à 0, puis de répéter un bloc de code tant que a est inférieur à 10, en augmentant la valeur de a à chaque itération.
int
a = 0;
for(;
a < 10;
){
...
}
L'objectif de ce code est de répéter un bloc de code tant que la variable a est inférieure à 10, en utilisant une initialisation préalable de a à 0 et en omettant l'actualisation de a à l'intérieur de la boucle.
Remarque: Une ou toutes les instructions d'initialisation, de condition ou d'actualisation peuvent être manquant.
int
a = 0;
for( a = 0;
a < 10;
a++){
...
a += 2 ;
...
}
L'objectif de ce code est d'initialiser la variable a à 0, puis de répéter un bloc de code tant que a est inférieur à 10, en augmentant la valeur de a de 2 à chaque itération à l'intérieur de la boucle, tout en incrémentant a de 1 avec l'opérateur a++ à chaque fin d'itération.
La boucle while maintient l'exécution d'un bloc de code tant que la condition entre les parenthèses reste vraie.
while(condition){
...
}

int
a = 20;
while(a > 0){
...
a--;
...
}
Ce code maintient la répétition d'un bloc de code tant que la valeur de la variable a est supérieure à 0, en la décrémentant à chaque itération.
int
a = 0;
while(a < 20){
...
a++;
...
}
Ce code vise à répéter un bloc de code tant que la valeur de la variable a est inférieure à 20, en l'incrémentant à chaque itération.
La boucle do..while garantit l'exécution d'un bloc de code au moins une fois avant de répéter son exécution tant que la condition spécifiée reste vraie.
do{
...
} while(condition);

int
a = 20;
do{
...
a --;
...
} while(a > 0);
Ce code exécute un bloc de code au moins une fois, puis le répète tant que la valeur de la variable a est supérieure à 0, en décrémentant a à chaque itération.
int
a = 0;
do{
...
a ++;
...
} while(a < 20);
Ce code garantit l'exécution d'un bloc de code au moins une fois, suivi de répétitions tant que la valeur de la variable a est inférieure à 20, en l'incrémentant à chaque itération.
L'instruction break est utilisée pour interrompre prématurément l'exécution d'une boucle (par exemple, for ou while) ou d'un bloc de commutation switch. Lorsque break est rencontré, le programme sort immédiatement de la structure de contrôle dans laquelle il se trouve, sans attendre la fin normale de la condition ou de la boucle. Cela permet de quitter la structure dès qu'une condition souhaitée est atteinte ou lorsqu'une sortie anticipée est nécessaire.
do{
...
if (condition 1) {
...
break;
}
...
} while(condition 2);
do{
...
if (condition 1) {
...
break;
}
...
} while(condition 2);
Ce code vise à exécuter un bloc de code au moins une fois, puis à répéter son exécution tant que condition 2 est vraie, tout en utilisant break pour sortir de la boucle si condition 1 est satisfaite.

L'instruction continue est utilisée pour passer immédiatement à l'itération suivante d'une boucle (par exemple, for ou while), en ignorant le reste du code à l'intérieur de la boucle pour cette itération particulière. Elle permet de sauter l'exécution des instructions restantes dans la boucle et de passer à la prochaine itération, ce qui est utile pour gérer des cas spécifiques sans quitter complètement la boucle.
do{
...
if (condition 1) {
...
continue;
}
...
} while(condition 2);
do{
...
if (condition 1) {
...
continue;
}
...
} while(condition 2);
Ce code a pour objectif d'exécuter un bloc de code au moins une fois, puis de le répéter tant que condition 2 est vraie, en utilisant continue pour sauter le reste du code dans une itération si condition 1 est satisfaite.

while(condition 1){
...
if (condition 2) {
...
break;
}
...
};
Dans ce code, l'objectif est d'exécuter un bloc de code tant que condition 1 est vraie, en utilisant break pour sortir de la boucle si condition 2 est satisfaite à l'intérieur de cette boucle.

while(condition 1){
...
if (condition 2) {
...
continue;
}
...
};
Dans ce code, l'objectif est d'exécuter un bloc de code tant que condition 1 est vraie, en utilisant continue pour passer à l'itération suivante de la boucle si condition 2 est satisfaite à l'intérieur de cette boucle.

for(initialisation;condition 1;actualisation){
...
if (condition 2) {
...
break;
}
...
};
L'objectif de ce code avec la boucle "for" est d'initialiser une variable, puis de répéter un bloc de code tant que condition 1 est vraie, en utilisant break pour sortir de la boucle si condition 2 est satisfaite à l'intérieur de celle-ci.

for(initialisation;condition 1;actualisation){
...
if (condition 2) {
...
continue;
}
...
};
L'objectif de ce code avec la boucle "for" est d'initialiser une variable, puis de répéter un bloc de code tant que condition 1 est vraie, en utilisant continue pour sauter le reste du code dans une itération si condition 2 est satisfaite à l'intérieur de la boucle.
