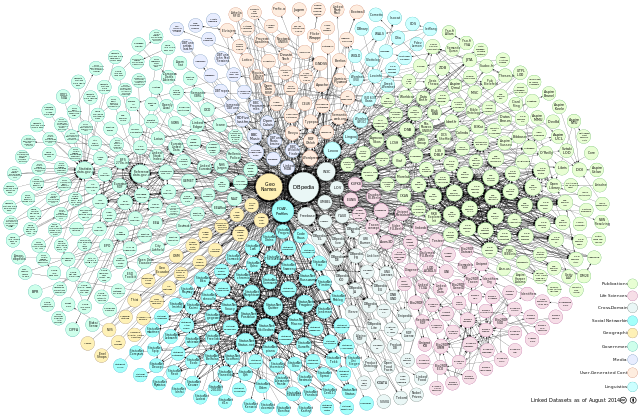
Traitement de données massives
John Samuel
CPE Lyon
Year: 2023-2024
Email: john.samuel@cpe.fr

John Samuel
CPE Lyon
Year: 2023-2024
Email: john.samuel@cpe.fr



\[f(x)=x\]
\[f'(x)=1\]

\[f(x) = \begin{cases} 0 & \text{for } x < 0\\ 1 & \text{for } x \ge 0 \end{cases} \]
\[f'(x) = \begin{cases} 0 & \text{for } x \ne 0\\ ? & \text{for } x = 0\end{cases}\]

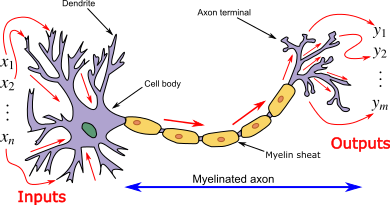
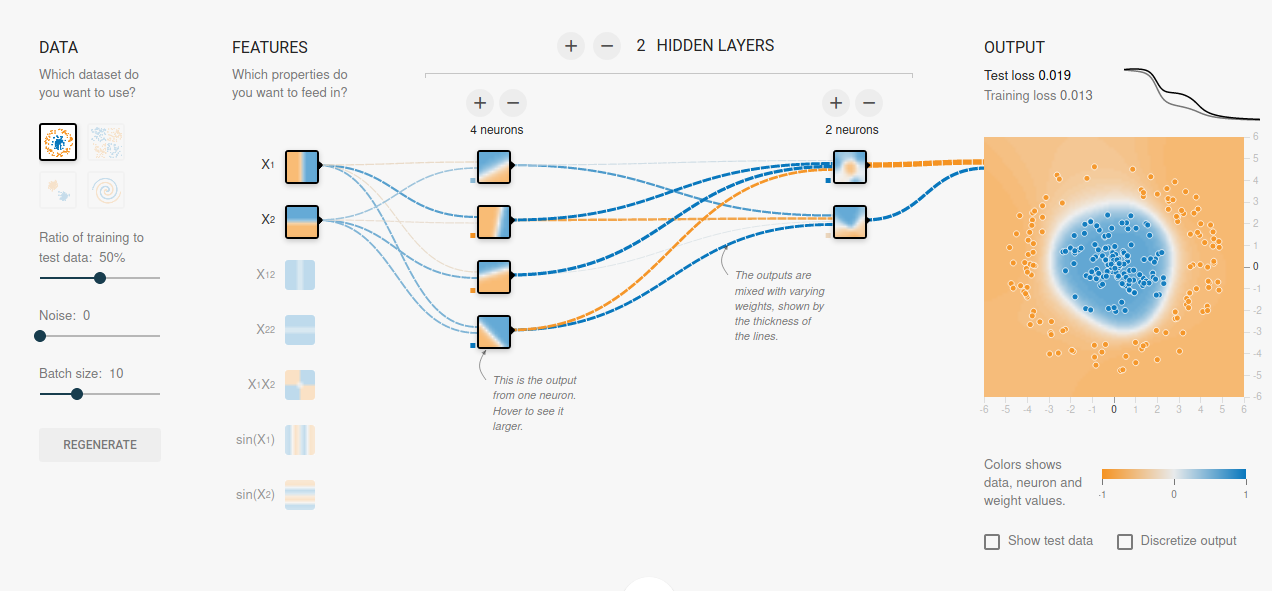
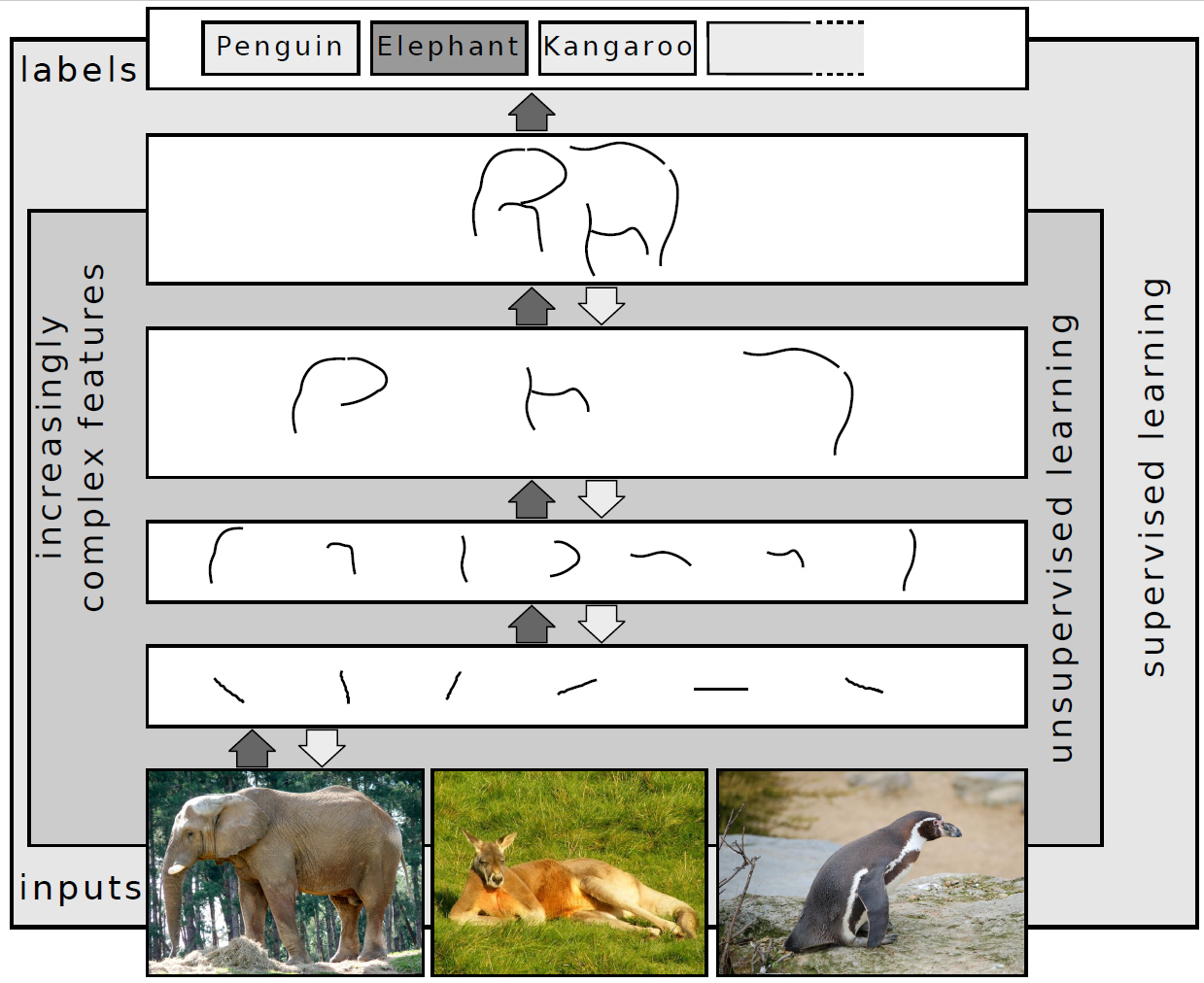
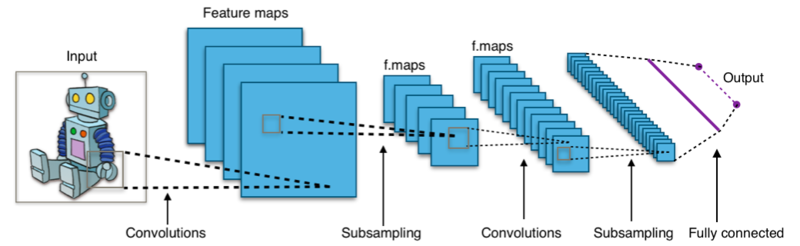
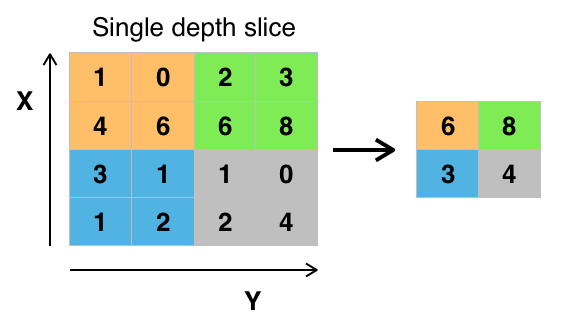
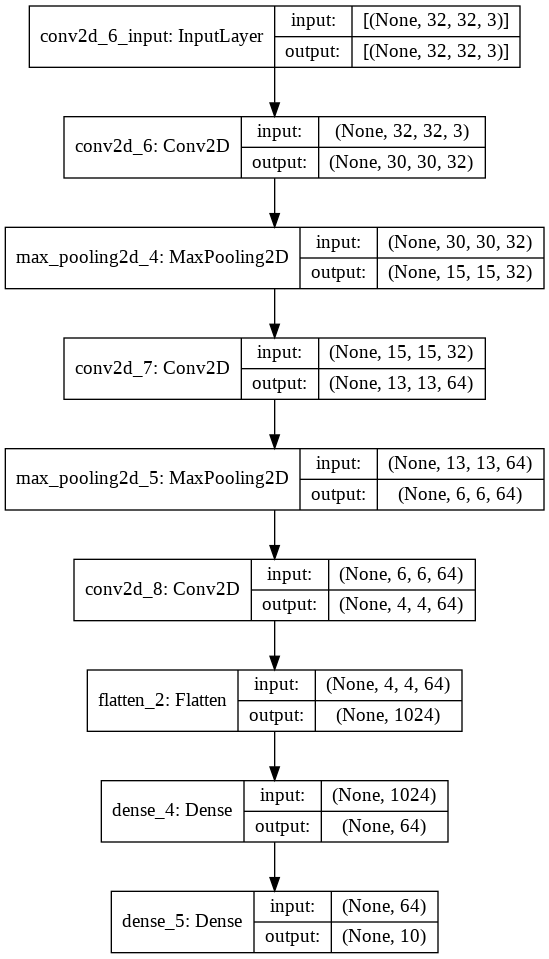
L'apprentissage par renforcement (RL) est une branche de l'apprentissage automatique où un agent interagit avec un environnement dynamique pour apprendre à prendre des décisions autonomes. Elle s'inspire des théories de psychologie animale, notamment du concept de renforcement dans le conditionnement opérant.