Data Mining et Machine Learning
John Samuel
CPE Lyon
Year: 2023-2024
Email: john.samuel@cpe.fr

John Samuel
CPE Lyon
Year: 2023-2024
Email: john.samuel@cpe.fr


Collecte initiale de données provenant de diverses sources.





Exploration approfondie des données pour identifier des tendances significatives et des insights pertinents.
Transformation des données en représentations graphiques claires et informatives. Par exemple, graphiques, tableaux de bord, cartes pour faciliter la compréhension visuelle.
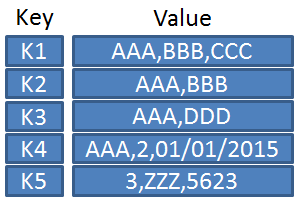
Format léger et lisible par l'homme pour représenter et échanger des données et une structure basée sur des paires clé-valeur, adaptée pour les objets complexes et les listes.
[
{
"languageLabel": "ENIAC coding system",
"year": "1943"
},
{
"languageLabel": "ENIAC Short Code",
"year": "1946"
},
{
"languageLabel": "Von Neumann and Goldstine graphing system",
"year": "1946"
}
]
Langage de balisage polyvalent pour représenter et structurer des données de manière lisible par l'homme et la machine. XML supporte la représentation de données complexes avec des schémas définissables.
<?xml version="1.0" encoding="UTF-8"?>
<root>
<element>
<languageLabel>ENIAC coding system</languageLabel>
<year>1943</year>
</element>
<element>
<languageLabel>ENIAC Short Code</languageLabel>
<year>1946</year>
</element>
<element>
<languageLabel>Von Neumann and Goldstine graphing system</languageLabel>
<year>1946</year>
</element>
</root>
Format de fichier texte utilisé pour représenter des données tabulaires sous forme de valeurs séparées par des virgules.Il est idéal pour stocker des données tabulaires comme les feuilles de calcul.
languageLabel,year ENIAC coding system,1943 ENIAC Short Code,1946 Von Neumann and Goldstine graphing system,1946

Il est impossible sur un système informatique de calcul distribué de garantir en même temps (c'est-à-dire de manière synchrone) les trois contraintes suivantes
Les bases de données NoSQL adoptent le modèle BASE en mettant l'accent sur la disponibilité immédiate des données et des opérations, même au détriment d'une cohérence instantanée.
.png)
Dans une base de données relationnelle, un tableau est une entité qui stocke des données organisées en lignes et colonnes. Les colonnes (Attributs) Représentent les différents types d'informations que la table stocke. Chaque colonne a un nom unique et un type de données spécifique (texte, nombre, date, etc.). Chaque ligne (tuple) représente un enregistrement individuel dans la table. Les lignes contiennent des données spécifiques, conformes à la structure définie par les colonnes. La clé primaire est une colonne spécifique ou une combinaison de colonnes utilisée pour identifier de manière unique chaque ligne dans la table.
| num | languageLabel | year |
|---|---|---|
| 1 | ENIAC coding system | 1943 |
| 2 | ENIAC Short Code | 1946 |
| 3 | Von Neumann and Goldstine graphing system | 1946 |
Dans une base de données orientée colonnes, les données sont stockées de manière efficace en utilisant une structure orientée colonnes plutôt que des lignes. Les données sont organisées en familles de colonnes, chaque famille ayant plusieurs colonnes liées à un identifiant unique. Elle est idéale pour les situations où l'accès à un sous-ensemble spécifique de données est fréquent. Elle est performante pour les agrégations et les opérations analytiques.
ENIAC coding system:1; ENIAC Short Code:2 Von Neumann and Goldstine graphing system:3 1943:1; 1946:2; 1946:3
Dans une base de données orientée documents, les données sont stockées sous forme de documents similaires à des objets JSON ou BSON. Les documents regroupent des données liées, souvent dans un format similaire à des paires clé-valeur ou des structures de données imbriquées. Elle permet une flexibilité de schéma, chaque document pouvant avoir des champs différents sans imposer une structure rigide. Elle est idéale pour les données semi-structurées ou changeantes fréquemment.
{
"languageLabel": "ENIAC coding system",
"year": "1943"
}
Exemples : MongoDB, CouchDB sont des exemples de bases de données NoSQL orientées documents.
Dans une base de données orientée clé-valeur, les données sont stockées sous forme de paires clé-valeur. Chaque donnée est associée à une clé unique, et ces paires clé-valeur peuvent être simples ou complexes. Elle offre une flexibilité maximale en termes de structure de données. Elle donne une excellente performance pour les opérations de lecture et d'écriture simples. Elle est idéale pour les cas d'utilisation nécessitant une récupération rapide de données par clé. Elle est performante pour le stockage de données simples et non structurées.
| identifiant | languageLabel,year |
|---|---|
| p1 | ENIAC coding system,1943 |
| p2 | ENIAC Short Code,1946 |
Exemples : Redis, Amazon DynamoDB sont des exemples de bases de données NoSQL orientées clé-valeur.
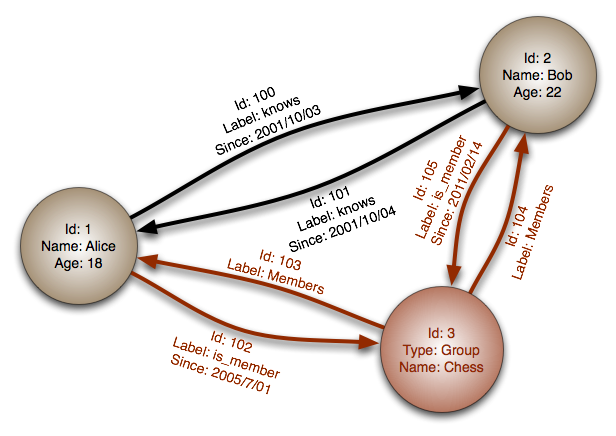
Dans une base de données orientée graphe, les données sont représentées sous forme de nœuds, d'arêtes et de propriétés. Les nœuds représentent les entités, les arêtes décrivent les relations entre ces entités, et les propriétés fournissent des informations supplémentaires. Elle est excellente pour modéliser des relations complexes entre différents types d'entités. Elle favorise la découverte de motifs et l'analyse de réseaux. Elle est idéale pour les domaines où les relations entre les données sont cruciales, comme les réseaux sociaux et les recommandations. Elle facilite l'analyse de la connectivité et des structures complexes.

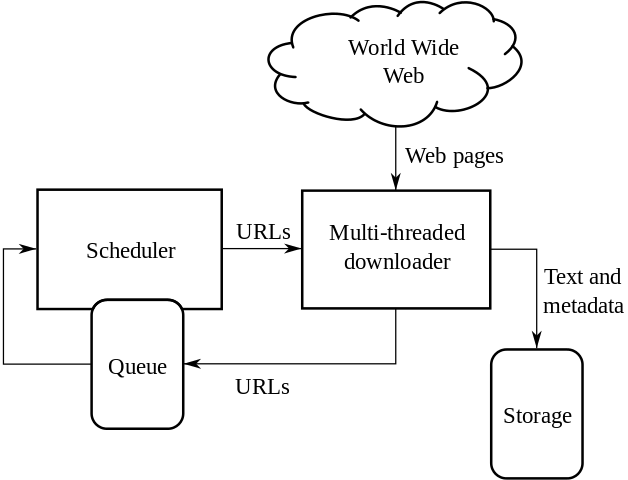
Les crawlers, également appelés robots d'indexation, sont des programmes qui parcourent et analysent automatiquement les pages web pour collecter des informations. Les crawlers naviguent de page en page en suivant les liens, extrayant des données pertinentes telles que le contenu, les liens hypertextes, les balises méta, etc.

import requests
url = "https://api.github.com/users/johnsamuelwrites"
response = requests.get(url)
print(response.json())
Identifie et corrige les anomalies pour garantir la qualité des données
<xs:schema attributeFormDefault="unqualified"
elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="root" type="rootType"/>
<xs:complexType name="elementType">
<xs:sequence>
<xs:element type="xs:string" name="languageLabel"/>
<xs:element type="xs:short" name="year"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="rootType">
<xs:sequence>
<xs:element type="elementType" name="element" maxOccurs="unbounded" minOccurs="0"/>
</xs:sequence>
</xs:complexType>
</xs:schema>
L'élimination des doublons implique la suppression d'enregistrements redondants en utilisant des contraintes d'intégrité, comme les dépendances fonctionnelles.
Exemple : Identifier les colonnes pertinentes qui définissent la duplication (par exemple, 'Colonne1', 'Colonne2'). Appliquer la suppression des doublons en conservant uniquement la première occurrence.
| num | languageLabel | year |
|---|---|---|
| 1 | ENIAC coding system | 1943 |
\({num}\rightarrow{languageLabel}\)
\({languageLabel}\rightarrow{year}\)
\({num}\rightarrow{year}\)
Déplacer efficacement les données des sources, telles que bases de données internes/externes et services web, vers les destinations, incluant entrepôts de données d'entreprise et entrepôts web, pour faciliter l'analyse.
Exploration des données selon plusieurs dimensions pour une compréhension approfondie.
Dimensions :Les aspects sous-jacents des données qui sont analysés.
Faits : Les mesures quantitatives associées aux dimensions, fournissant les données à analyser.
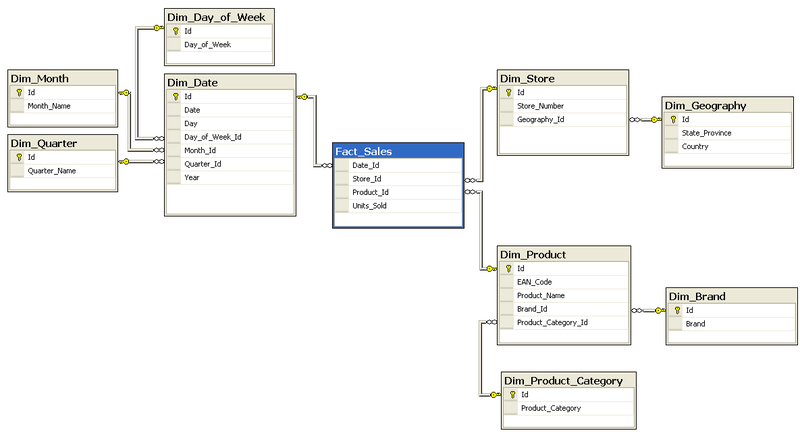
Le modèle de données en étoile est une architecture de base de données conçue spécifiquement pour faciliter l'analyse et le reporting dans les entrepôts de données.
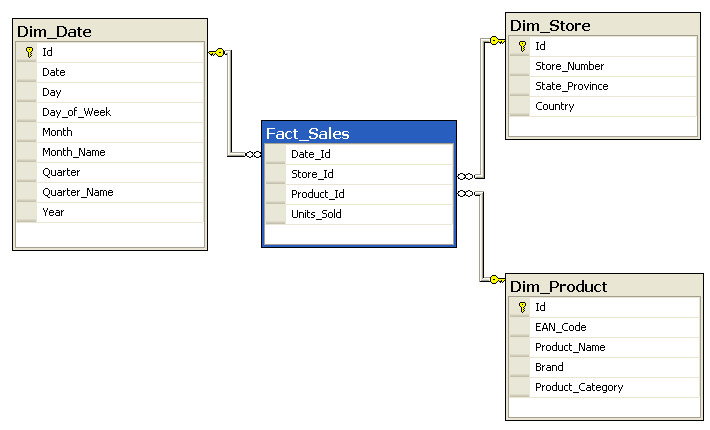
Dans le modèle de données en étoile, les cubes de données, également appelés hypercubes, sont des structures multidimensionnelles qui permettent une analyse approfondie.
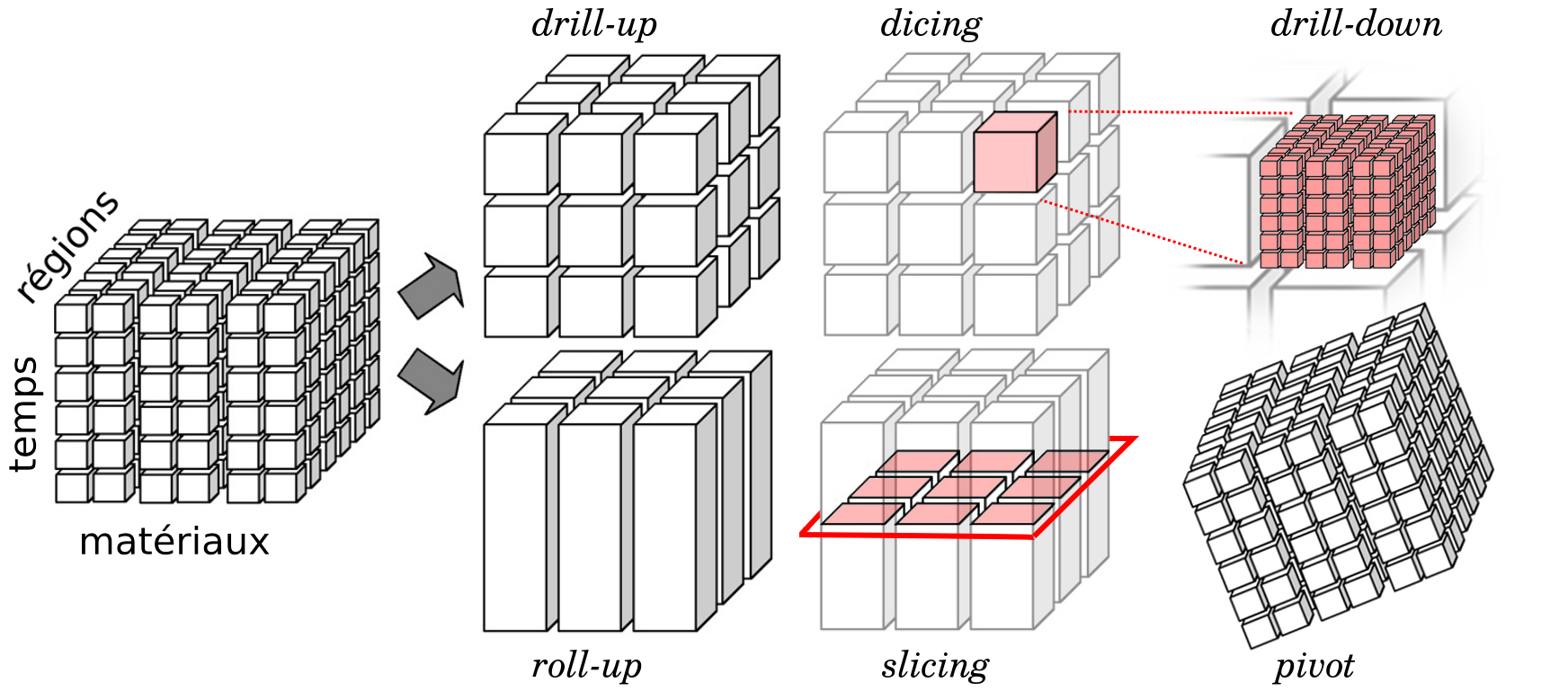
Cubes de Données pour le Traitement Analytique en Ligne (OLAP) : - Les cubes de données sont essentiels pour les systèmes OLAP, facilitant l'analyse multidimensionnelle.Les opérations OLAP permettent aux utilisateurs d'interagir avec les cubes pour obtenir des analyses spécifiques.
Le modèle de données en flocon est une variante du modèle en étoile, conçu pour réduire la redondance en normalisant les dimensions.
Jacques Bertin identifie différentes variables visuelles cruciales pour la représentation graphique des données.