Apprentissage profond
John Samuel
CPE Lyon
Year: 2023-2024
Email: john(dot)samuel(at)cpe(dot)fr

John Samuel
CPE Lyon
Year: 2023-2024
Email: john(dot)samuel(at)cpe(dot)fr
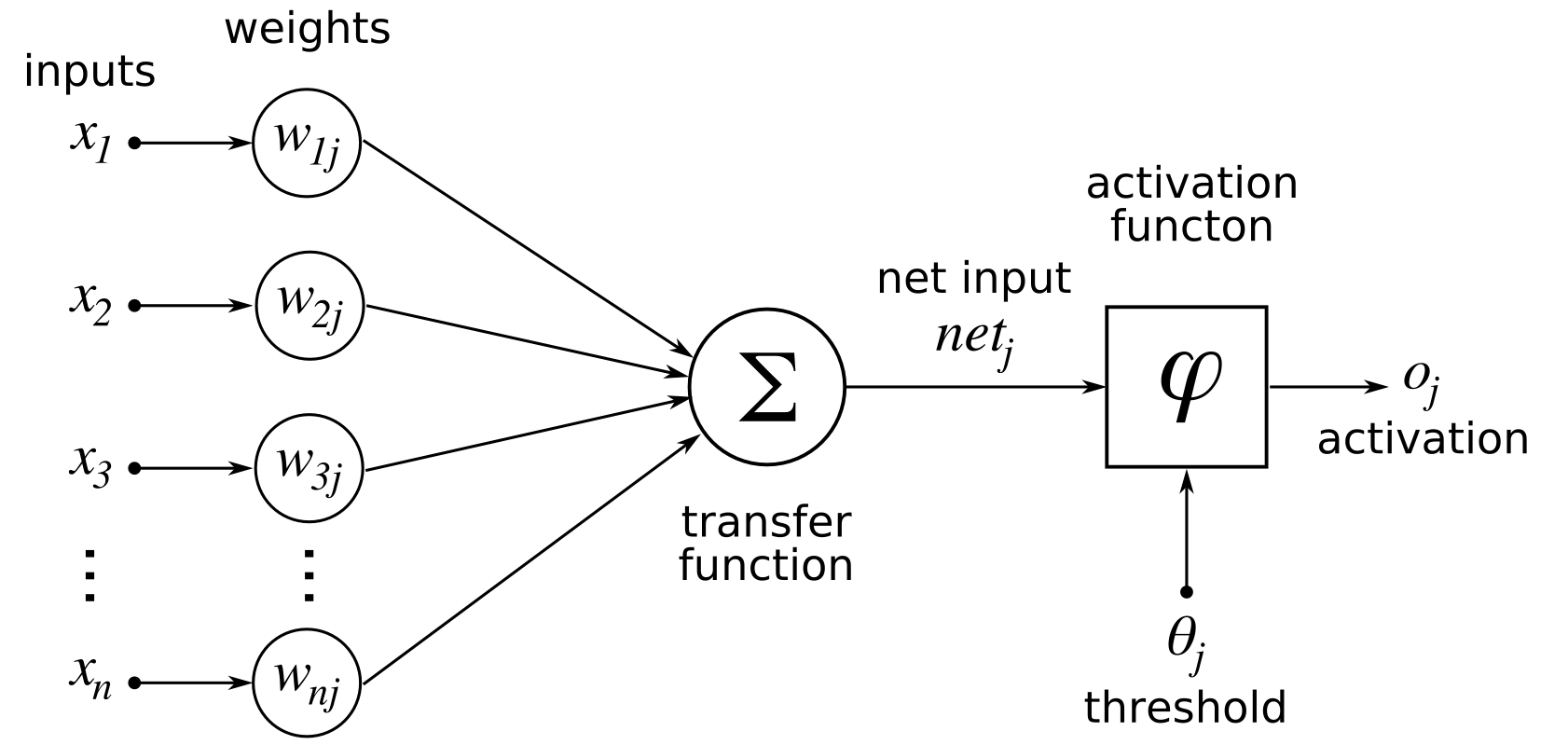
Le perceptron à simple couche, bien qu'il ait été une avancée significative dans le développement des réseaux de neurones artificiels, présente certaines limites importantes qui restreignent sa capacité à résoudre des problèmes complexes. Voici quelques-unes des principales limitations du perceptron à simple couche :
Pour surmonter ces limitations, des architectures plus complexes telles que les réseaux de neurones profonds avec plusieurs couches cachées ont été développées. Ces réseaux permettent une représentation plus riche et non linéaire des données, rendant possible la résolution de problèmes plus complexes.
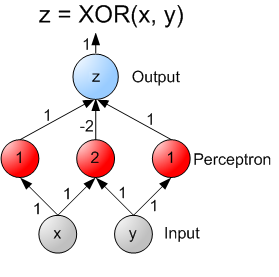
Le perceptron multicouche, également appelé réseau de neurones à plusieurs couches, surmonte plusieurs des limitations du perceptron à simple couche en introduisant des couches cachées et des fonctions d'activation non linéaires.
# Importation des bibliothèques nécessaires de TensorFlow
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
# Étape 1: Création d'un modèle séquentiel
model = Sequential()
# Étape 2: Ajout d'une couche dense avec une fonction d'activation ReLU
# La couche a 4 neurones, une fonction d'activation 'relu', et prend une entrée de forme (3,)
model.add(Dense(4, activation='relu', input_shape=(3,)))
# Étape 3: Ajout d'une couche dense de sortie avec une fonction d'activation softmax
# La couche a 2 neurones pour une tâche de classification binaire, et softmax est utilisé
# pour obtenir des probabilités
model.add(Dense(units=2, activation='softmax'))
# Étape 4: Compilation du modèle
# Utilisation de la descente de gradient stochastique (SGD) comme optimiseur avec un taux d'apprentissage de 0.01
# La fonction de perte est 'mean_squared_error' pour un problème de régression
# Les performances du modèle seront mesurées en termes de 'accuracy' (précision)
sgd = SGD(lr=0.01)
model.compile(loss='mean_squared_error', optimizer=sgd, metrics=['accuracy'])
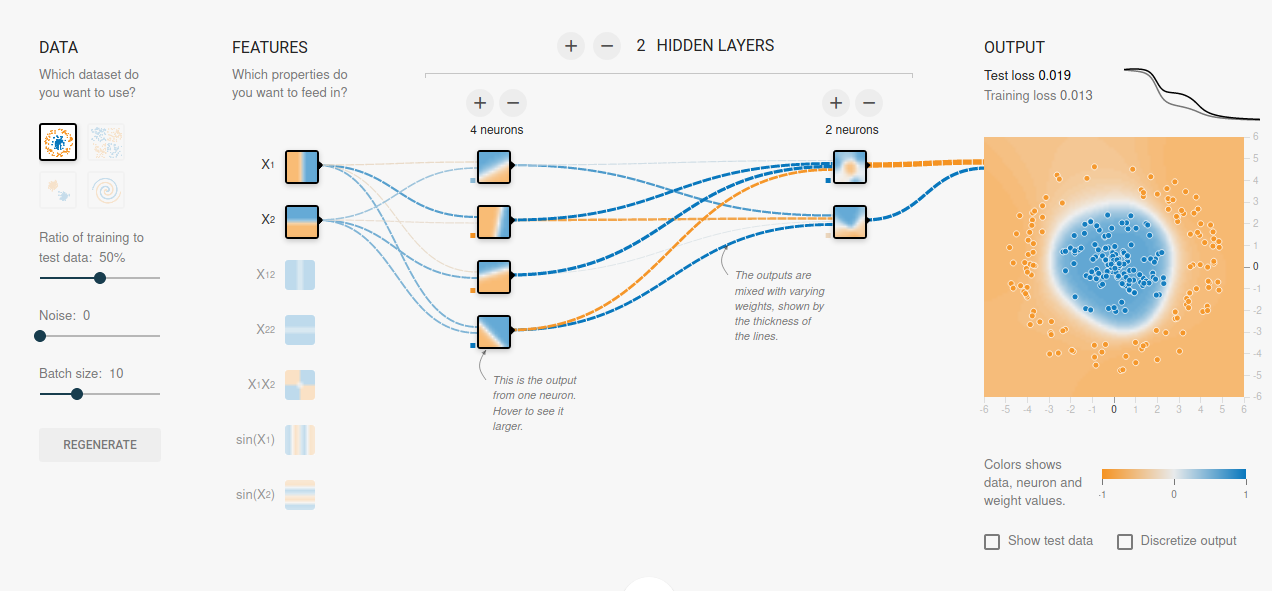
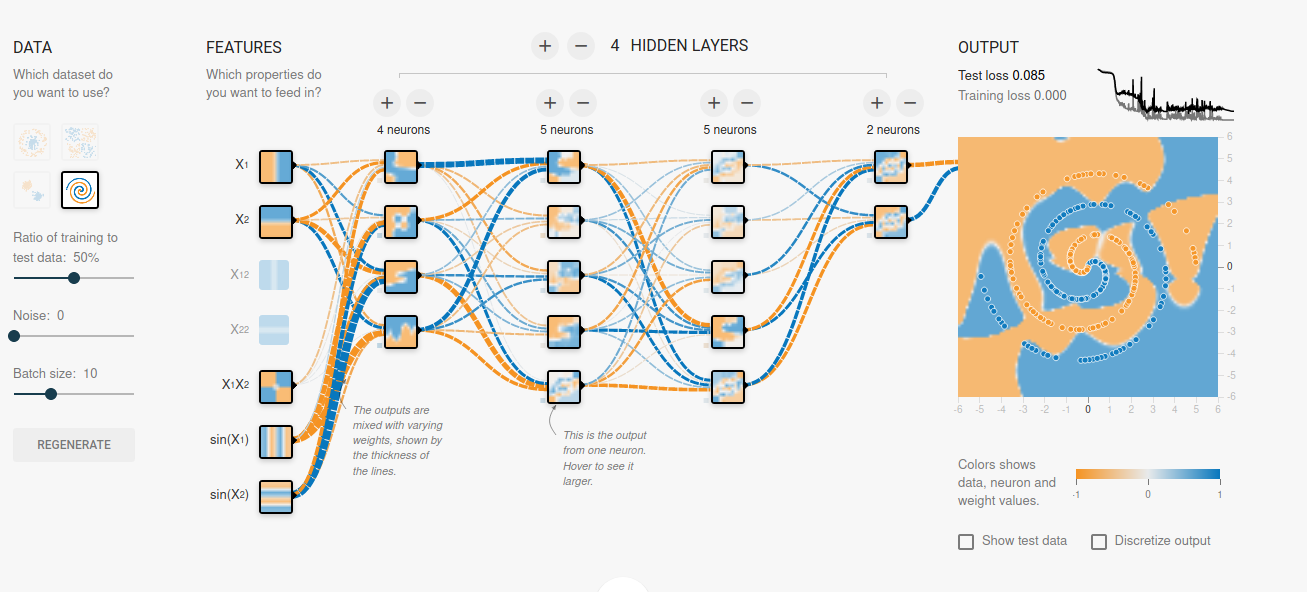
Un réseau de neurones profond est une architecture complexe où l'information circule de la couche d'entrée à travers les couches cachées jusqu'à la couche de sortie. Chaque connexion entre les neurones est associée à un poids qui est ajusté pendant le processus d'apprentissage pour optimiser les performances du modèle sur la tâche spécifique. L'utilisation de plusieurs couches cachées permet au réseau d'apprendre des représentations de plus en plus abstraites et complexes des données.
Connectivité entièrement connectée: Dans une connectivité entièrement connectée, chaque neurone d'une couche est connecté à chaque neurone de la couche suivante. Cela signifie que toutes les informations de la couche précédente sont transmises à chaque neurone de la couche suivante. C'est la configuration la plus courante dans les couches totalement connectées, généralement présentes dans les parties du réseau proches de la sortie.
Connectivité par le biais de la mise en commun (Pooling)
Réseaux de Neurones en Aval (Feedforward Neural Networks) :
Les réseaux de neurones en aval, sont plus adaptés à des tâches où chaque exemple de données peut être traité de manière indépendante.
Réseaux Récurrents
La connectivité récurrente dans les réseaux récurrents permet aux informations de persister et d'être mises à jour à chaque itération ou pas de temps, ce qui les rend adaptés à des tâches séquentielles.
Les hyperparamètres sont des paramètres constants dont la valeur est fixée avant le début du processus d'apprentissage d'un réseau de neurones artificiels. Contrairement aux paramètres du modèle, qui sont appris pendant l'entraînement, les hyperparamètres sont des choix de conception qui influencent la manière dont le modèle est formé. Voici quelques exemples d'hyperparamètres couramment utilisés dans les réseaux de neurones :
Le réglage judicieux de ces hyperparamètres est souvent crucial pour obtenir des performances optimales d'un modèle de réseau de neurones. Il implique souvent des expérimentations et des ajustements itératifs pour trouver la combinaison optimale pour une tâche d'apprentissage spécifique.
| Réseaux | Nombre de couches |
|---|---|
| AlexNet | 8 |
| VGGNet | 16 |
| InceptionNet | 27 |
| GoogleNet | 22 |
| ResNet | 50, 101, 152, 200, 345 |
| DenseNet | 121, 169, 201 |
| MobileNetV2 | 13, 16, 23 |
ReLU (Rectified Linear Unit) :La fonction ReLU est largement utilisée en raison de sa simplicité et de sa capacité à introduire une non-linéarité. Elle remplace les valeurs négatives par zéro, permettant au réseau d'apprendre des représentations complexes. \[f(x) = \max(0, x)\]
Sigmoid : Souvent utilisée en couche de sortie pour les problèmes de classification binaire, car elle ramène les valeurs à l'intervalle [0, 1], pouvant être interprétées comme des probabilités. \[f(x) = \frac{1}{1 + e^{-x}}\]
Tanh (Tangente hyperbolique) : Similaire à la fonction sigmoïde, mais ramène les valeurs à l'intervalle [-1, 1]. Elle est souvent utilisée en tant que fonction d'activation pour les couches cachées. \[f(x) = \frac{e^{2x} - 1}{e^{2x} + 1}\]
Softmax : Principalement utilisée en couche de sortie pour les problèmes de classification multiclasse. Elle transforme les scores en probabilités. \[f(x)_i = \frac{e^{x_i}}{\sum_{j}e^{x_j}}\] pour chaque \(i\)-ème élément du vecteur \(x\)
Les fonctions de perte (loss functions) sont des métriques qui mesurent à quel point les prédictions d'un modèle diffèrent des valeurs réelles attendues. Choisir la bonne fonction de perte dépend du type de problème que vous essayez de résoudre, qu'il s'agisse d'une tâche de classification, de régression, ou autre.
| Fonction de Perte | Type de Problème | Utilisation |
|---|---|---|
| Mean Squared Error (MSE) | Régression | \( \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 \) - Mesure l'erreur quadratique moyenne entre les prédictions (\( \hat{y}_i \)) et les valeurs réelles (\( y_i \)). Utile lorsque les erreurs doivent être pénalisées de manière significative. |
| Fonction de Perte | Type de Problème | Utilisation |
|---|---|---|
| Mean Absolute Error (MAE) | Régression | \( \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| \) - Mesure l'erreur absolue moyenne entre les prédictions (\( \hat{y}_i \)) et les valeurs réelles (\( y_i \)). Moins sensible aux valeurs aberrantes que le MSE. | Binary Crossentropy | Classification Binaire | \( -\frac{1}{n} \sum_{i=1}^{n} \left(y_i \cdot \log(\hat{y}_i) + (1-y_i) \cdot \log(1-\hat{y}_i)\right) \) - Fonction de perte pour la classification binaire. Convient lorsque chaque exemple d'entraînement appartient à une seule classe. |
| Fonction de Perte | Type de Problème | Utilisation |
|---|---|---|
| Categorical Crossentropy | Classification Multiclasse | \( -\frac{1}{n} \sum_{i=1}^{n} \sum_{j=1}^{m} y_{i,j} \cdot \log(\hat{y}_{i,j}) \) - Fonction de perte pour la classification multiclasse. Convient lorsque chaque exemple d'entraînement peut appartenir à plusieurs classes. |
| Hinge Loss | SVM (Support Vector Machine) | \( \frac{1}{n} \sum_{i=1}^{n} \max(0, 1 - y_i \cdot \hat{y}_i) \) - Utilisé pour les machines à vecteurs de support. Pénalise les erreurs lorsque la prédiction (\( \hat{y}_i \)) n'est pas du bon côté de la marge. |
| Fonction de Perte | Type de Problème | Utilisation |
|---|---|---|
| Huber Loss | Régression | \( \frac{1}{n} \sum_{i=1}^{n} L_{\delta}(y_i - \hat{y}_i) \) - Une combinaison de MSE et MAE. Moins sensible aux valeurs aberrantes que MSE et moins impacté par celles-ci que MAE. |
| Poisson Loss | Régression (Poisson) | \( \frac{1}{n} \sum_{i=1}^{n} \left(\hat{y}_i - y_i \cdot \log(\hat{y}_i) \right) \) - Utilisé pour des tâches de régression où les valeurs suivent une distribution de Poisson. |
| Optimiseur | Description |
|---|---|
| Stochastic Gradient Descent (SGD) | L'optimiseur de descente de gradient stochastique classique. Il met à jour les poids du modèle en se déplaçant dans la direction opposée du gradient moyen calculé sur un petit lot de données d'entraînement à la fois. |
| Adam (Adaptive Moment Estimation) | Un optimiseur qui combine des idées de RMSprop et de Momentum. Il adapte les taux d'apprentissage des paramètres en fonction de leurs gradients moyens et de leurs moments moyens. Très populaire et souvent recommandé pour de nombreuses tâches. |
| Optimiseur | Description |
|---|---|
| RMSprop (Root Mean Square Propagation) | Ajuste les taux d'apprentissage pour chaque paramètre individuellement en utilisant une moyenne pondérée exponentielle des carrés des gradients. Cela aide à atténuer les problèmes liés aux taux d'apprentissage dans la descente de gradient stochastique. |
Les réseaux de neurones en aval, également appelés réseaux de neurones à propagation avant (Feedforward Neural Networks), se caractérisent par une architecture où les connexions entre les nœuds ne forment pas de cycles. L'information se déplace de manière unidirectionnelle, des nœuds d'entrée vers les nœuds de sortie, sans boucles récurrentes.
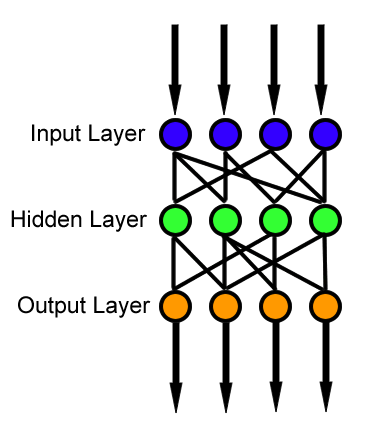
La rétropropagation du gradient, également appelée backpropagation, est une technique clé utilisée dans l'apprentissage des réseaux de neurones pour ajuster les poids des connexions afin de minimiser l'erreur globale du modèle.
La rétropropagation est un processus itératif qui se déroule sur plusieurs cycles (itérations ou époques) d'entraînement du modèle. Elle contribue de manière significative à l'apprentissage des représentations et à l'amélioration des performances du réseau de neurones.
La rétropropagation du gradient implique le calcul des gradients de la fonction de perte par rapport aux poids du réseau. Pour expliquer le processus plus en détail, nous allons utiliser quelques notations courantes. Supposons que \(L\) soit la fonction de perte, \(w_{ij}^{(k)}\) soit le poids entre le neurone \(i\) dans la couche \(k-1\) et le neurone \(j\) dans la couche \(k\), et \(a_{i}^{(k)}\) soit l'activation du neurone \(i\) dans la couche \(k\).
Ces calculs sont effectués pour chaque exemple d'entraînement dans un lot (batch), et l'algorithme d'optimisation ajuste les poids pour minimiser la fonction de perte sur l'ensemble des données d'entraînement. Le processus est répété sur plusieurs époques jusqu'à ce que le modèle atteigne une performance souhaitée.
Les réseaux de neurones récurrents (RNN) sont un type de réseau de neurones où les connexions entre les nœuds forment un graphe dirigé le long d'une séquence temporelle. Cela leur permet de présenter un comportement dynamique temporel, ce qui les rend particulièrement adaptés au traitement de séquences de données.
Les RNN sont largement utilisés dans des applications qui impliquent des données séquentielles, notamment :

Dans un réseau de neurones récurrents (RNN), le neurone, également appelé unité récurrente, est l'élément de base qui permet au réseau de traiter des données séquentielles en maintenant un état interne ou une mémoire.
Entrées : Le neurone RNN reçoit deux types d'entrées :
Formule Générale : La sortie du neurone à l'instant \(t\) est calculée comme suit :
\[ h_t = \text{fonction_activation}(w_{hx} \cdot x_t + w_{hh} \cdot h_{t-1} + b_h) \] \(w_{hx}\) et \(w_{hh}\) sont les poids associés aux entrées actuelles et à l'état caché précédent, respectivement. \(b_h\) est le terme de biais.
Le rôle principal du neurone dans un RNN est de traiter séquentiellement les données en maintenant une mémoire du passé à travers l'état caché. Cette capacité à conserver des informations antérieures permet au RNN de modéliser des dépendances à long terme dans les séquences temporelles, ce qui est crucial pour des tâches telles que la reconnaissance de la parole, la traduction automatique, etc.
Avantages
Limites
Les unités LSTM sont une variation de l'architecture des réseaux neuronaux récurrents (RNN) conçue pour résoudre le problème du gradient qui disparaît ou explose lors de l'entraînement de séquences à long terme. Elles sont particulièrement utiles pour modéliser les dépendances à long terme dans les séquences temporelles, telles que des séquences de mots dans le langage naturel.

Ensemble, ces composants permettent à une unité LSTM de maintenir et de gérer des informations sur des périodes de temps étendues, ce qui en fait un choix puissant pour la modélisation de séquences temporelles complexes. Les portes d'entrée, de sortie et d'oubli fournissent un mécanisme de régulation fin pour contrôler le flux d'informations à travers la cellule.
Supposons que \(x_t\) soit l'entrée à l'instant de temps \(t\), \(h_{t-1}\) soit la sortie de la couche LSTM à l'instant de temps précédent \(t-1\), et \(c_{t-1}\) soit l'état de la cellule à l'instant de temps précédent \(t-1\).
Porte d'entrée (Input Gate) :
Mise à jour de la cellule :
Porte de sortie (Output Gate) :
Dans ces équations :
Ces équations décrivent le flux d'information à travers une unité LSTM, avec des portes d'entrée, de sortie et d'oubli régulant l'interaction entre l'entrée, l'état de la cellule et la sortie. Ces formules permettent aux LSTM de maintenir et de gérer l'information sur des intervalles de temps arbitraires, ce qui les rend efficaces pour la modélisation de séquences temporelles complexes.
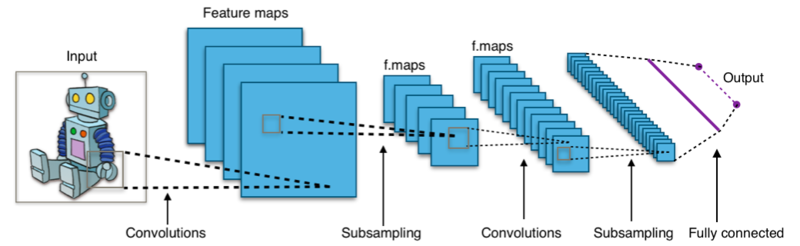
Les réseaux de neurones convolutionnels (CNN) sont une classe d'architectures de réseaux neuronaux conçues principalement pour l'analyse des images. Ils ont été particulièrement efficaces dans des tâches telles que la classification d'images, la détection d'objets, et la segmentation d'images.
En résumé, les CNN suivent une architecture hiérarchique, où les couches convolutives apprennent des caractéristiques locales, et ces caractéristiques sont ensuite combinées dans les couches suivantes pour former des représentations plus complexes. La non-linéarité introduite par la fonction d'activation ReLU est cruciale pour permettre au modèle d'apprendre des relations non linéaires dans les données.
Un noyau dans le contexte du traitement d'images, également appelé filtre ou masque, est une petite matrice qui est appliquée sur une image à l'aide d'une opération de convolution. L'objectif de l'application de ces noyaux est de réaliser diverses opérations de filtrage sur l'image, telles que la détection de contours, l'amélioration des détails, la mise en évidence de certaines caractéristiques, etc.
Il s'agit d'un noyau simple qui conserve l'image d'origine sans apporter de modifications. Lorsque ce noyau est appliqué à une image, il laisse l'image inchangée.
\( \begin{matrix} \ \ 0 &\ \ 0 &\ \ 0 \\ \ \ 0 &\ \ 1 &\ \ 0 \\ \ \ 0 &\ \ 0 &\ \ 0 \end{matrix} \)
Ce noyau est conçu pour détecter les contours dans une image. Il est également connu sous le nom de filtre de Sobel. Lorsqu'il est appliqué à une image, ce noyau met en évidence les variations d'intensité qui indiquent la présence de contours.
\( \begin{matrix} \ \ 1 & 0 & -1 \\ \ \ 0 & 0 & \ \ 0 \\ -1 & 0 & \ \ 1 \end{matrix} \)
Ce noyau est utilisé pour réaliser une opération de flou simple. Il est également connu sous le nom de flou moyen. Lorsqu'il est appliqué à une image, ce noyau attribue à chaque pixel la moyenne des valeurs de ses voisins, ce qui produit un effet de flou.
\( \frac{1}{9} \begin{matrix} 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{matrix} \)
Ce noyau est basé sur une distribution gaussienne et est utilisé pour réaliser un flou plus doux et plus esthétique. L'idée ici est que les pixels du centre ont un poids plus élevé, créant ainsi un effet de flou qui ressemble à celui généré par une lentille de caméra.
\( \frac{1}{16} \begin{matrix} 1 & 2 & 1 \\ 2 & 4 & 2 \\ 1 & 2 & 1 \end{matrix} \)
La convolution est le processus central qui consiste à appliquer un noyau (aussi appelé filtre) sur une image. Cela se fait en déplaçant le noyau sur l'ensemble de l'image, multipliant les valeurs des pixels correspondants et produisant une nouvelle image appelée carte de caractéristiques.
\[ \begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1n} \\ x_{21} & x_{22} & \cdots & x_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ x_{m1} & x_{m2} & \cdots & x_{mn} \\ \end{bmatrix} * \begin{bmatrix} y_{11} & y_{12} & \cdots & y_{1n} \\ y_{21} & y_{22} & \cdots & y_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ y_{m1} & y_{m2} & \cdots & y_{mn} \\ \end{bmatrix} = \sum^{m-1}_{i=0} \sum^{n-1}_{j=0} x_{(m-i)(n-j)} y_{(1+i)(1+j)} \]
Après la convolution, des opérations de pooling (souvent max pooling ou moyenne pooling) sont effectuées pour réduire la dimension de la carte de caractéristiques en préservant les informations importantes.
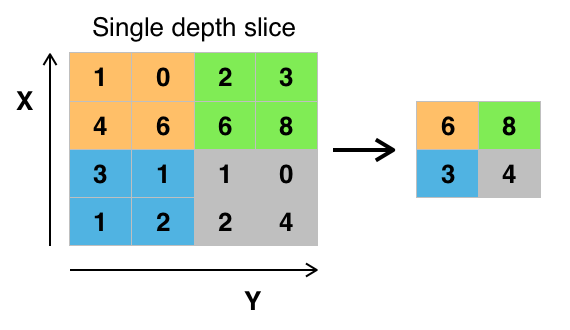
Stride : Contrôle le déplacement du noyau sur l'image. Un stride de 1 signifie un déplacement pixel par pixel, tandis qu'un stride plus grand réduit la taille de la carte de caractéristiques.
Padding : Ajoute des pixels autour de l'image d'entrée pour maintenir la taille de la sortie après la convolution.
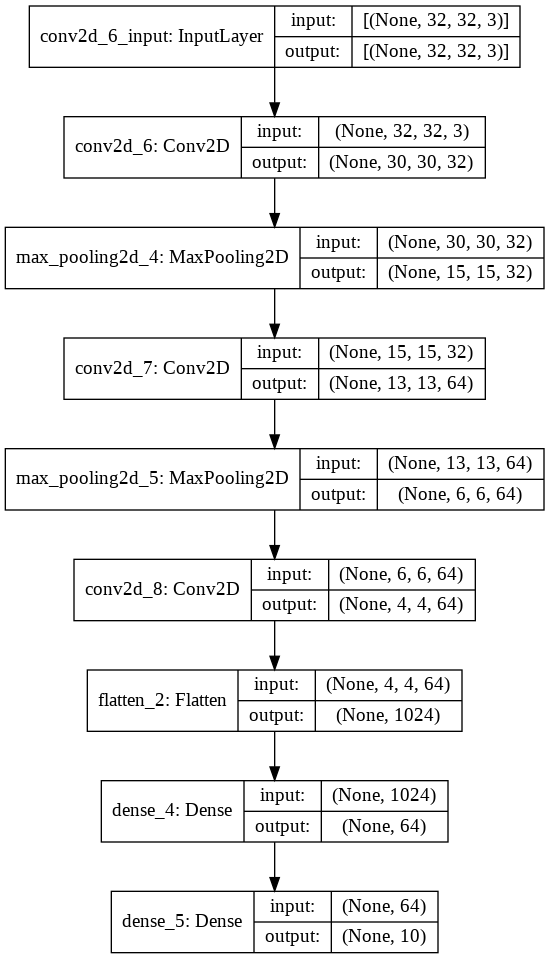
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0
# Créer un modèle séquentiel (réseaux de neurones convolutionnels)
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10)
#Compilation du modèle
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
Les réseaux de neurones récurrents convolutifs (RCNN) sont une famille de modèles d'apprentissage automatique pour la vision par ordinateur, en particulier la détection d'objets. Ils combinent les avantages des réseaux de neurones récurrents (RNN) et des réseaux de neurones convolutifs (CNN).
Bi-RCNN est une variante de RCNN qui utilise des réseaux de neurones récurrents bidirectionnels (Bi-RNN) pour améliorer la précision de la détection d'objets. Les Bi-RNN sont des modèles qui peuvent traiter des séquences de données dans les deux sens. Ils sont capables de capturer la dépendance entre les éléments d'une séquence, tant dans le passé que dans le futur. Dans le contexte de la détection d'objets, les Bi-RNN peuvent être utilisés pour capturer la relation entre les objets dans une image. Par exemple, un Bi-RNN peut être utilisé pour déterminer si deux objets sont proches l'un de l'autre, ou s'ils sont de la même classe.
Bi-RCNN est une méthode prometteuse pour améliorer la précision de la détection d'objets. Elle a été utilisée avec succès dans une variété de tâches, telles que la détection de personnes, la détection de véhicules et la détection de visages.