Apprentissage machine
John Samuel
CPE Lyon
Year: 2023-2024
Email: john(dot)samuel(at)cpe(dot)fr

John Samuel
CPE Lyon
Year: 2023-2024
Email: john(dot)samuel(at)cpe(dot)fr

Vous recevrez un courrier détaillé avant l'examen
| Cours | Nombre d'heures |
|---|---|
| Cours | 16 |
| TP | 16 |
| Projet | 16 |
Attention : À chaque séance, nous adopterons un format intégrant à la fois des cours et des travaux pratiques.

Les propositions dans la logique propositionnelle sont des déclarations qui peuvent être vraies (V) ou fausses (F). Supposons que nous ayons deux propositions simples : P, Q. Nous pouvons utiliser des connecteurs logiques pour créer des propositions plus complexes à partir de ces propositions simples.
Supposons que nous ayons quatre propositions simples : P, Q, R et S.
Avec ces propositions, nous pouvons définir des règles pour déterminer si une image représente la mer :
nous pouvons utiliser des opérateurs logiques pour combiner ces propositions et déterminer si l'image est celle de la mer :
Image de la mer : (P ET Q) OU (P ET R) OU (P ET S)
Contrairement à la logique propositionnelle, qui traite uniquement de la vérité ou de la fausseté de propositions simples, la logique du premier ordre permet de représenter des informations structurées sur des objets et leurs relations. Voici quelques concepts clés de la logique du premier ordre :
Utilisez des parenthèses pour indiquer la priorité des opérations et la structure de la formule.
Utilisez des parenthèses pour indiquer la priorité des opérations et la structure de la formule.
Exemple :
Exemple :
Les fonctions sont utilisées pour attribuer des valeurs à des objets ou effectuer des opérations, tandis que les prédicats sont utilisés pour exprimer des relations ou des propriétés entre des objets et renvoient une valeur booléenne indiquant si la relation est vraie ou non.
Utilisons l'exemple des règles pour confirmer qu'une image représente effectivement une mer.
1. Pour déterminer si une image représente une scène de mer, nous pourrions utiliser une règle du type
∀x (ContientEau(x) ∧ ContientSable(x) => EstMer(x))
2. Nous pourrions également ajouter des règles spécifiques pour détecter des éléments spécifiques :
∀x (ContientBateaux(x) => EstPort(x))
∀x (ContientOiseauxMarins(x) => EstPlage(x))
3. Il existe au moins une image x telle que l'image contienne de l'eau et du sable.
∃x (ContientEau(x) ∧ ContientSable(x))
La logique modale est une extension de la logique classique qui permet de raisonner sur la notion de "modalités", c'est-à-dire des catégories de propositions qui expriment des modalités ou des qualités spécifiques, telles que la nécessité, la possibilité, l'obligation, la croyance, etc
Opérateurs modaux : Les opérateurs modaux sont utilisés pour exprimer des modalités. Les deux opérateurs modaux les plus courants sont :
En logique modale, les termes "nécessaire", "contingent", "possible" et "impossible" sont utilisés pour décrire les modalités ou les qualités d'une proposition.
Exemple
Le raisonnement automatisé est un domaine de l'intelligence artificielle (IA) qui concerne la création de systèmes informatiques capables de tirer des conclusions logiques et de résoudre des problèmes de manière autonome, similaire à la manière dont les humains utilisent leur raisonnement pour résoudre des problèmes.
Le raisonnement automatisé peut être expliqué en utilisant différentes logiques, notamment la logique propositionnelle, la logique du premier ordre et la logique modale.
La représentation des connaissances joue un rôle central dans la manière dont les systèmes informatiques comprennent, raisonnent et interagissent avec le monde. La représentation des connaissances désigne le processus de capture, de structuration et de stockage des informations et des connaissances de manière à les rendre utilisables par des systèmes informatiques. Cela implique de transformer des données brutes ou des concepts en une forme que les ordinateurs peuvent comprendre et exploiter pour résoudre des problèmes, prendre des décisions ou interagir avec les utilisateurs.
Les types de connaissances peuvent être classés en plusieurs catégories, notamment les connaissances déclaratives, les connaissances procédurales, les connaissances explicites et les connaissances tacites.
Dans la représentation des connaissances déclaratives, les faits, les informations et les connaissances sont exprimés sous forme de propositions logiques.
Graphes de Connaissances (Ontologies): Les ontologies sont des structures de données hiérarchiques qui organisent et hiérarchisent les connaissances en utilisant des concepts, des classes, des propriétés et des relations.
Les agents intelligents sont des entités logicielles ou matérielles capables de percevoir leur environnement, de prendre des décisions, et d'agir pour atteindre des objectifs spécifiques. Un agent intelligent est un système informatique ou une entité physique qui possède certaines caractéristiques clés :
Les agents intelligents peuvent être classés en différents types en fonction de leurs caractéristiques et de leurs capacités.
Dans l'apprentissage profond, le terme profond fait référence à la présence de multiples couches dans le réseau neuronal. Contrairement aux modèles plus simples, tels que les perceptrons monocouche, les réseaux profonds ont la capacité d'apprendre des représentations hiérarchiques complexes à partir de données brutes.
L'apprentissage machine, également connu sous le nom de machine learning (ML), est un domaine de l'intelligence artificielle (IA) qui se concentre sur le développement de techniques permettant aux ordinateurs d'apprendre à partir de données. L'objectif principal de l'apprentissage machine est de permettre aux systèmes informatiques de prendre des décisions ou de réaliser des tâches sans être explicitement programmés, en s'appuyant sur des modèles et des motifs appris à partir des données.
L'apprentissage machine occupe une place centrale dans le paysage technologique actuel et a un impact significatif dans divers domaines.
La construction de caractéristiques est une étape essentielle dans le pipeline de prétraitement des données en apprentissage machine, car elle peut aider à rendre les données plus informatives pour les algorithmes d'apprentissage.
Cette formalisation est au cœur de l'apprentissage supervisé, où l'objectif est d'apprendre à partir d'exemples étiquetés et de trouver une fonction qui puisse prédire de manière précise les étiquettes pour de nouvelles données non vues.
L'apprentissage non supervisé est utilisé pour explorer et découvrir des modèles, des structures ou des caractéristiques inhérentes aux données, sans l'utilisation d'étiquettes ou de labels préalables. Il est couramment utilisé dans des domaines tels que la clustering, l'analyse de composantes principales (PCA), l'analyse en composantes indépendantes (ICA), et bien d'autres.

Dans le contexte de la classification en apprentissage machine, l'évaluation des performances d'un modèle implique la compréhension de différents types de prédictions qu'il peut faire par rapport à la réalité. Les vrais positifs (VP) et les vrais négatifs (VN) sont deux de ces éléments.


Soit
La précision mesure la proportion de prédictions positives faites par le modèle qui étaient effectivement correctes, tandis que le rappel mesure la proportion d'exemples positifs réels qui ont été correctement identifiés par le modèle. Alors
Le F1-score est la moyenne harmonique de la précision et du rappel. Il fournit une mesure globale de la performance d'un modèle de classification, tenant compte à la fois de la précision et du rappel. Il est particulièrement utile lorsque les classes sont déséquilibrées.
Le F1-score tient compte à la fois des erreurs de type I (faux positifs) et des erreurs de type II (faux négatifs), fournissant ainsi une mesure équilibrée de la performance du modèle.
Le \(F_2\)-score est souvent utilisé dans des domaines où le rappel est considéré comme plus critique que la précision.
La matrice de confusion est un outil essentiel dans l'évaluation des performances d'un système de classification. Elle fournit une vue détaillée des prédictions faites par le modèle par rapport aux classes réelles.




Prendre des décisions signifie appliquer tous les classificateurs à un échantillon invisible x et prédire l'étiquette k pour laquelle le classificateur correspondant rapporte le score de confiance le plus élevé : \[\hat{y} = \underset{k \in \{1 \ldots K\}}{\arg\!\max}\; f_k(x)\]

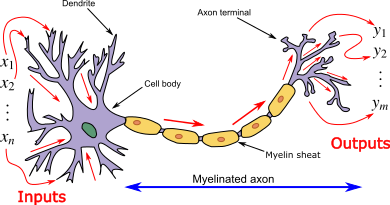

Les réseaux de neurones sont couramment utilisés dans le domaine de l'apprentissage machine, en particulier dans des tâches telles que la classification, la régression, la reconnaissance d'images, le traitement du langage naturel, et bien d'autres. Un réseau de neurones artificiels est une collection d'unités interconnectées appelées neurones artificiels. Ces réseaux sont inspirés de la structure du cerveau biologique
Les neurones sont organisés en couches. Il existe généralement trois types de couches dans un réseau de neurones :
L'objectif global de l'entraînement est d'ajuster les poids du réseau de manière à ce qu'il puisse généraliser à de nouvelles données, produisant des résultats précis pour des exemples qu'il n'a pas vu pendant l'entraînement.
Chaque neurone artificiel a des entrées, qui peuvent être les valeurs caractéristiques d'un échantillon de données externe, et produit une seule sortie. Cette sortie peut être envoyée à plusieurs autres neurones, formant ainsi la structure interconnectée du réseau neuronal. La fonction d'activation joue un rôle crucial dans le calcul de la sortie d'un neurone. Le processus comprend les étapes suivantes :
Le réseau de neurones est constitué de connexions, où chaque connexion transmet la sortie d'un neurone comme entrée à un autre neurone. Chaque connexion possède un poids qui représente son importance relative dans la transmission du signal.
Calcul de l'entrée d'un neurone : La fonction de propagation calcule l'entrée d'un neurone en prenant la somme pondérée des sorties de ses prédécesseurs, où chaque sortie est multipliée par le poids de la connexion correspondante. Cela peut être représenté mathématiquement comme suit :
\[ \text{Entrée du Neurone} = \sum_{i=1}^{n} (\text{Sortie du Prédécesseur}_i \times \text{Poids}_i) \] où \(n\) est le nombre de connexions d'entrée.
Ajout d'un terme de biais : Un terme de biais peut être ajouté au résultat de la propagation. Le terme de biais est un paramètre supplémentaire, souvent représenté par \(b\) dans les équations, qui permet au modèle d'apprendre un décalage ou une translation. Cela donne la forme finale de l'entrée du neurone :
\[ \text{Entrée du Neurone} = \sum_{i=1}^{n} (\text{Sortie du Prédécesseur}_i \times \text{Poids}_i) + \text{Biais} \]
Fonction d'Activation : Après avoir calculé l'entrée du neurone, celle-ci est passée à travers une fonction d'activation. Cette fonction introduit une non-linéarité dans le modèle, permettant au réseau de neurones de capturer des relations complexes et d'apprendre des modèles non linéaires. Certaines des fonctions d'activation couramment utilisées comprennent :
Le perceptron est un algorithme d'apprentissage supervisé utilisé pour la classification binaire. Il est conçu pour résoudre des problèmes où l'objectif est de déterminer si une entrée donnée appartient ou non à une classe particulière.


Le perceptron utilise généralement une fonction d'activation simple, et la fonction d'échelon (step function) est fréquemment choisie pour cette tâche.
La fonction d'échelon attribue une sortie de 1 si la somme pondérée des entrées dépasse un certain seuil, et 0 sinon.
\( f(x) = \begin{cases} 1 & \text{si } x \geq \text{seuil} \\ 0 & \text{sinon} \end{cases} \)
\[f(x)=x\]
\[f'(x)=1\]

\[f(x) = \begin{cases} 0 & \text{for } x < 0\\ 1 & \text{for } x \ge 0 \end{cases} \]
\[f'(x) = \begin{cases} 0 & \text{for } x \ne 0\\ ? & \text{for } x = 0\end{cases}\]

\[f(x)=\sigma(x)=\frac{1}{1+e^{-x}}\]
\[f'(x)=f(x)(1-f(x))\]

\[f(x)=\tanh(x)=\frac{(e^{x} - e^{-x})}{(e^{x} + e^{-x})}\]
\[f'(x)=1-f(x)^2\]

\[f(x) = \begin{cases} 0 & \text{for } x \le 0\\ x & \text{for } x > 0\end{cases} = \max\{0,x\}= x \textbf{1}_{x>0}\]
\[f'(x) = \begin{cases} 0 & \text{for } x \le 0\\ 1 & \text{for } x > 0\end{cases}\]

\[f(x)=e^{-x^2}\]
\[f'(x)=-2xe^{-x^2}\]

Un réseau de neurones profond, également connu sous le nom de réseau de neurones profondément hiérarchisé ou réseau neuronal profond (DNN pour Deep Neural Network en anglais), est un type de réseau de neurones artificiels qui comprend plusieurs couches de traitement, généralement plus de deux. Ces réseaux sont appelés "profonds" en raison de leur architecture empilée de couches, permettant la création de représentations hiérarchiques complexes des données.
Architecture en couches : Les réseaux de neurones profonds sont composés de multiples couches, généralement divisées en trois types principaux :
L'entraînement de réseaux de neurones profonds peut nécessiter des volumes importants de données et de puissance de calcul.
Il existe plusieurs types de réseaux de neurones profonds.