Data Science
John Samuel
CPE Lyon
Année: 2023-2024
Email: john.samuel@cpe.fr

John Samuel
CPE Lyon
Année: 2023-2024
Email: john.samuel@cpe.fr

Les cadrans solaires témoignent de l'ingéniosité scientifique de l'antiquité. Ils ont influencé le développement ultérieur des instruments astronomiques.









Sortie de données : Facilitation de la visualisation des informations traitées.
Usage commercial : Adoption répandue dans les environnements professionnels.



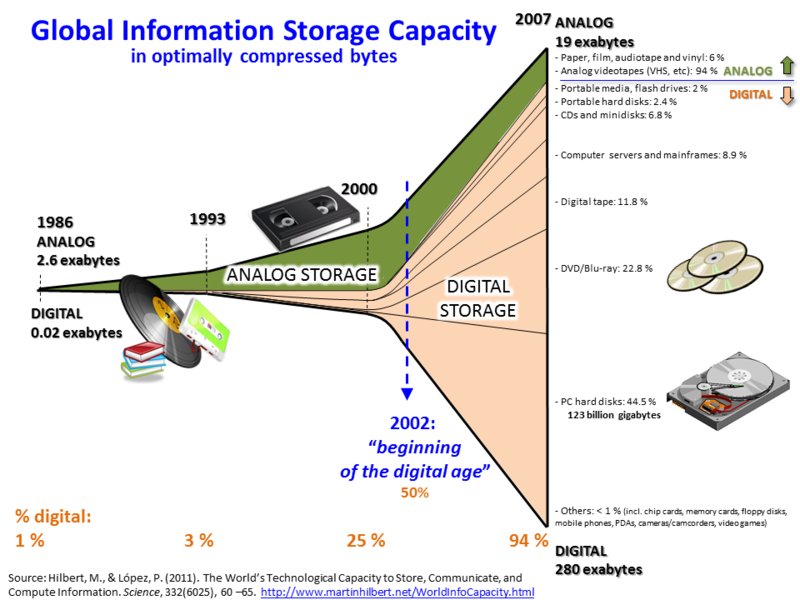
Serveurs : Impact sur les méthodes de stockage de données et contribution à la gestion centralisée des données.


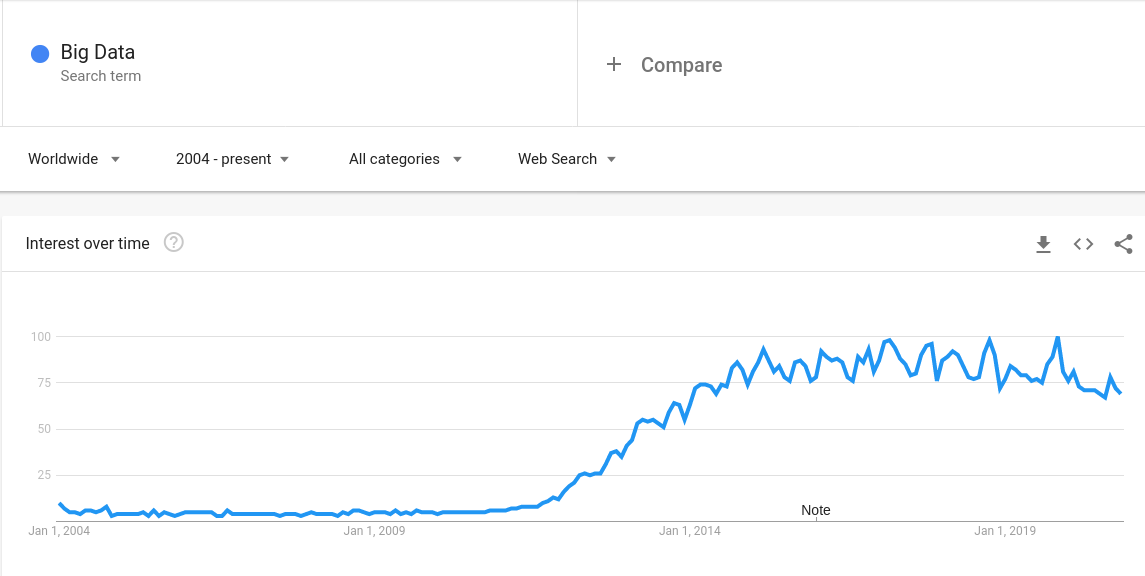
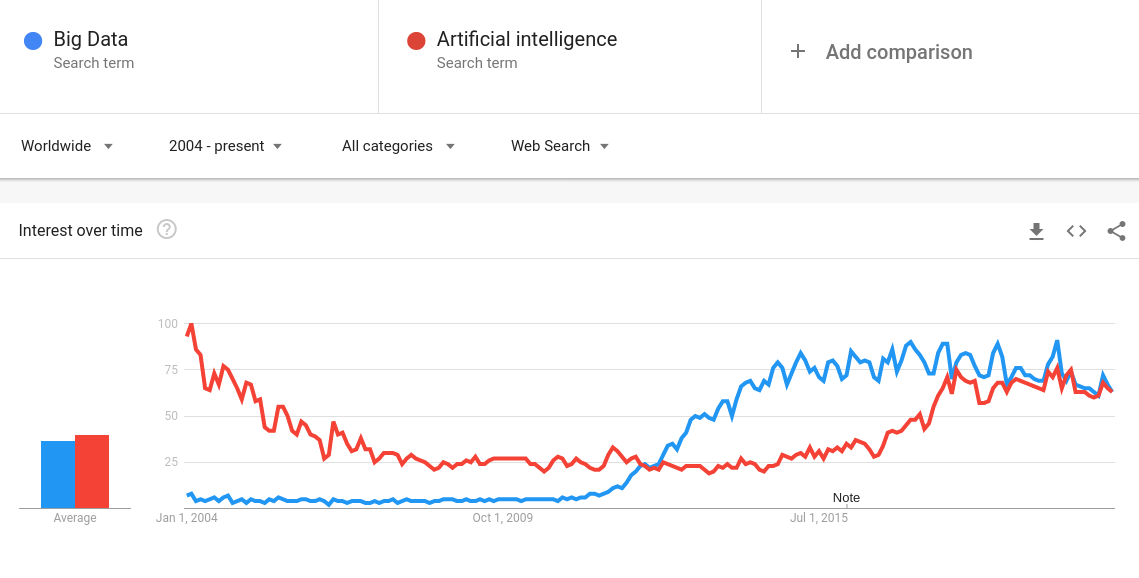
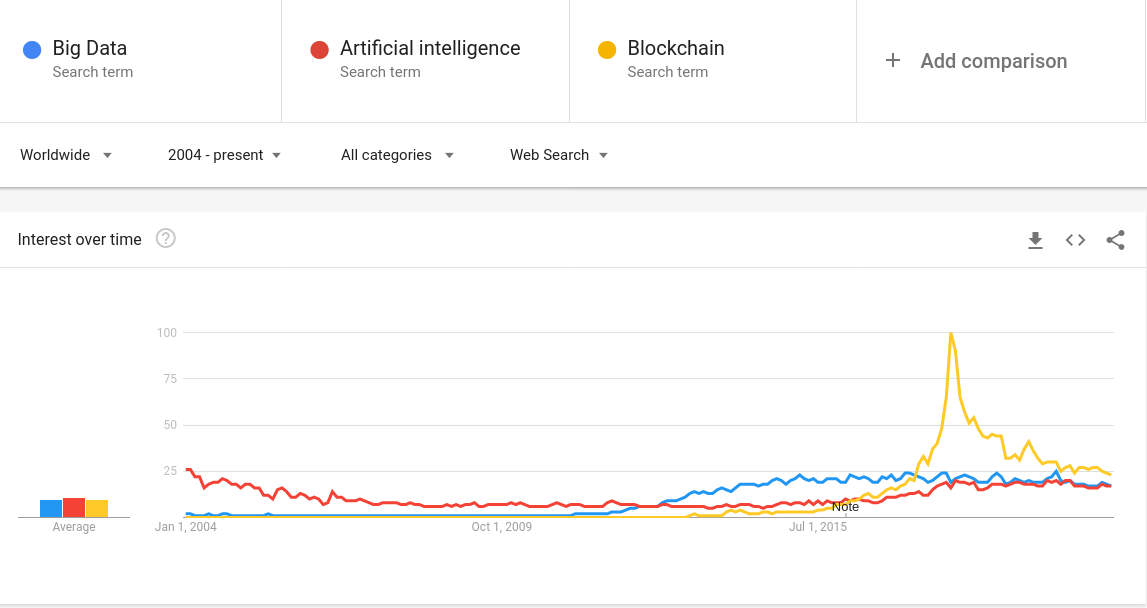



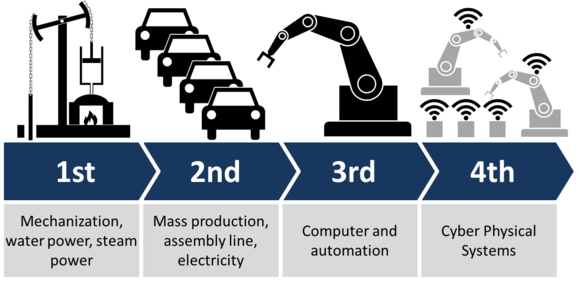

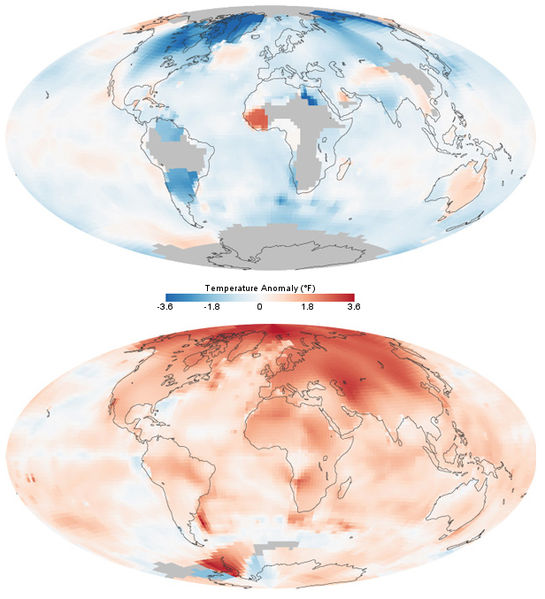
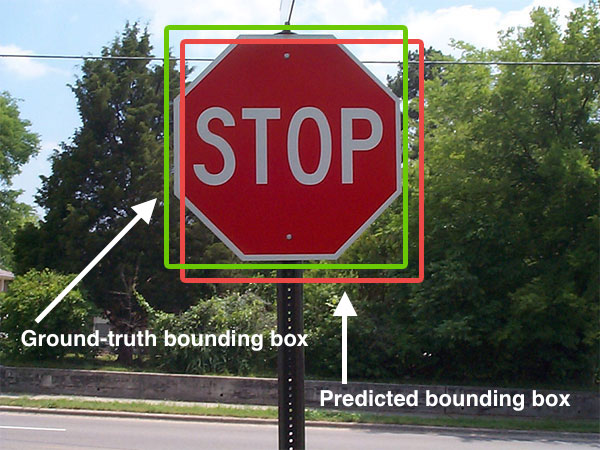





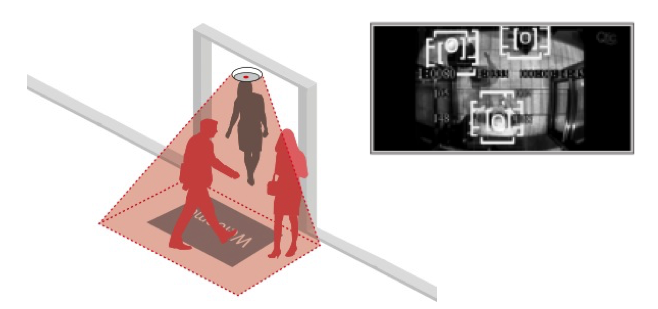





Caissier : Acteur principal dans l'acquisition de données au point de vente.

Acquisition de données dans le domaine de l'e-commerce : Enregistrement des transactions, détails des produits, informations de paiement, et données sur les clients.
Guichet Automatique Bancaire: point d'acquisition de données cruciales dans le secteur financier.

Méthode d'acquisition de données par l'utilisation de capteurs de température.
Méthode d'acquisition de données à travers l'utilisation de caméras vidéo : enregistrement visuel continu de scènes spécifiques.

Acquisition de données à partir des médias et des plateformes de réseaux sociaux : collecte d'informations provenant de publications, commentaires, partages, et interactions en ligne.

Méthode d'acquisition de données impliquant la contribution du grand public : collecte de données provenant d'un grand nombre de participants en ligne. Les données incluent des idées, des avis, des contributions créatives, reflétant la diversité des participants.

Exemple de production participative dans le domaine des données : contributions massives à des projets tels que Wikipédia, Wikibooks, et autres.
from urllib import request
response = request.urlopen("https://en.wikipedia.org/wiki/Main_Page")
html = response.read()
from urllib import request
from lxml import html
document = html.parse(request.urlopen("https://en.wikipedia.org/wiki/Main_Page"))
for link in document.iter("a"):
if(link.get("href") is not None):
print(link.base_url+link.get("href"))

import requests
url = "https://api.github.com/users/johnsamuelwrites"
response = requests.get(url)
print(response.json())
import requests
url = "https://api.github.com/users/johnsamuelwrites/repos"
response = requests.get(url)
print(response.json())
from SPARQLWrapper import SPARQLWrapper, JSON
sparql = SPARQLWrapper("http://query.wikidata.org/sparql")
sparql.setQuery("""
SELECT ?item WHERE {
?item wdt:P31 wd:Q9143;
}
LIMIT 10
""")
sparql.setReturnFormat(JSON)
results = sparql.query().convert()
for result in results["results"]["bindings"]:
print(result)
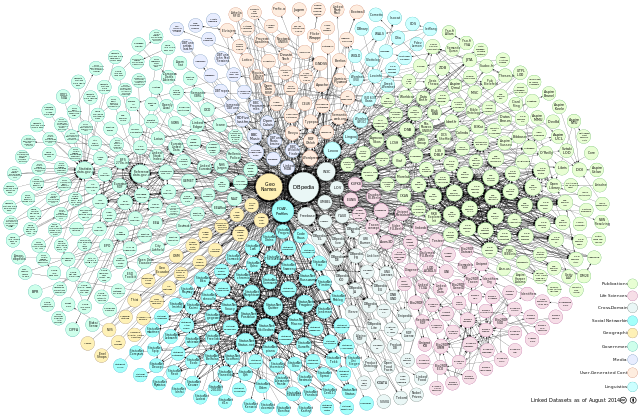



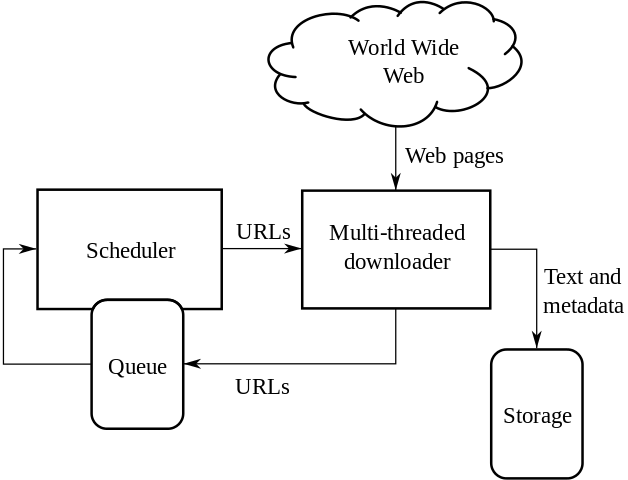
Exploration approfondie des données pour identifier des tendances significatives et des insights pertinents.