
Objectifs
- Introduction de numpy, matplotlib et pandas
- Manipulation des fichiers CSV et JSON
- Analyse des données
Evaluation
Chaque exercice a un niveau de difficulté. Les exercices faciles et de difficulté moyenne vous aident pour comprendre les fondamentaux. Il est recommandé de finir ces exercices avant de commencer les exercices difficiles. Le niveau de difficulté de l'exercice:
- ★: Facile
- ★★: Moyen
- ★★★: Difficile
Exercice 1 ★
1. Version de numpy
import numpy
print(numpy.__version__)
import numpy as np
print(np.__version__)
2. Tableau
import numpy as np
a = np.array([1, 2, 3, 4])
print(a)
print(type(a))
import numpy as np
a = np.array([1, 2, 3, 4])
print(a.shape)
3. Tableau à deux dimensions
import numpy as np
a = np.array([[1, 2, 3, 4], [5,6,7,8]])
print(a.shape)
4. Tableau à trois dimensions
import numpy as np
a = np.array([[[1, 2], [5,6]], [[1, 2], [5,6]]])
print(a.shape)
print(a.ndim)
import numpy as np
a = np.array([[[1, 2], [5,6]], [[1, 2], [5,6]]])
print(a.dtype)
import numpy as np
a = np.array([[[1.1, 2.2], [5.3,6.4]], [[1.4, 2.5], [5.5,6.4]]])
print(a.dtype)
import numpy as np
a = np.array([[[1.1, 2.2], [5.3,6.4]], [[1.4, 2.5], [5.5,6.4]]])
print(a.ndim)
import numpy as np
a = np.array([[[1.1, 2.2], [5.3,6.4]], [[1.4, 2.5], [5.5,6.4]]])
print(a.itemsize)
5. Opérations
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([[4, 5], [6, 7]])
c = a + b
print(c)
c = a - b
print(c)
c = a * b
print(c)
d = np.dot(a, b)
print(d)
6. Forme
import numpy as np
a = np.array([1,2,3,4,5,6,7,8])
print(a)
print(a.shape)
b = a.reshape(4,2)
print(b)
print(b.shape)
b = a.reshape(2,4)
print(b)
print(b.shape)
b = a.reshape(2,2,2)
print(b)
print(b.shape)
Exercice 2 ★★
1. Graphique avec matplotlib
import matplotlib.pyplot as plt
import numpy as np
a = np.array([1,2,3,4,5,6,7,8])
b = np.array([1,2,3,4,5,6,7,8])
plt.plot(a,b)
import matplotlib.pyplot as plt
import numpy as np
a = np.array([1,2,3,4,5,6,7,8])
b = np.array([1,4,9,16,25,36,49,64])
plt.plot(a,b)
2. Lecture de fichiers CSV et tracer les données.
Copier ce fichier CSV dans votre répertoire. Le fichier contient la population entre 1901 et 2016. Tracer un graphique.
import numpy as np
dataset = np.loadtxt("population.csv", dtype={'names': ('year', 'population'), 'formats': ('i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
print(dataset)
Exécutez le code ci-dessous et comparez la différence.
import numpy as np
year, population = np.loadtxt("population.csv", dtype={'names': ('year', 'population'), 'formats': ('i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8", unpack= True)
print(year)
import numpy as np
import matplotlib.pyplot as plt
year, population = np.loadtxt("population.csv", dtype={'names': ('year', 'population'), 'formats': ('i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8", unpack= True)
plt.plot(year, population)
plt.show()
3. Diagramme en barres
import numpy as np
import matplotlib.pyplot as plt
year, population = np.loadtxt("population.csv", dtype={'names': ('year', 'population'), 'formats': ('i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8", unpack= True)
plt.bar(year, population)
plt.show()
import matplotlib.pyplot as plot
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [0, 1, 0, 0, 1, 0, 1, 1, 1, 0]
plot.plot(x, y, linewidth=3, drawstyle="steps", color="#00363a")
plot.show()
import numpy as np
import matplotlib.pyplot as plt
year, population = np.loadtxt("population.csv", dtype={'names': ('year', 'population'), 'formats': ('i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8", unpack= True)
plt.plot(year, population, linewidth=3, drawstyle="steps", color="#00363a")
plt.show()
Exercice 3 ★★
1. Manipulation des données
import numpy as np
dataset = np.loadtxt("population.csv", dtype={'names': ('year', 'population'), 'formats': ('i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
print(dataset[:]['year'])
print(dataset[:]['population'])
import numpy as np
dataset = np.loadtxt("population.csv", dtype={'names': ('year', 'population'), 'formats': ('i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
print(dataset[0:10]['year'])
2. Analyse des données
import numpy as np
dataset = np.loadtxt("population.csv", dtype={'names': ('year', 'population'), 'formats': ('i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
population = dataset[:]['population']
print(population.max())
print(population.min())
print(population.mean())
print(population.std())
print(population.sum())
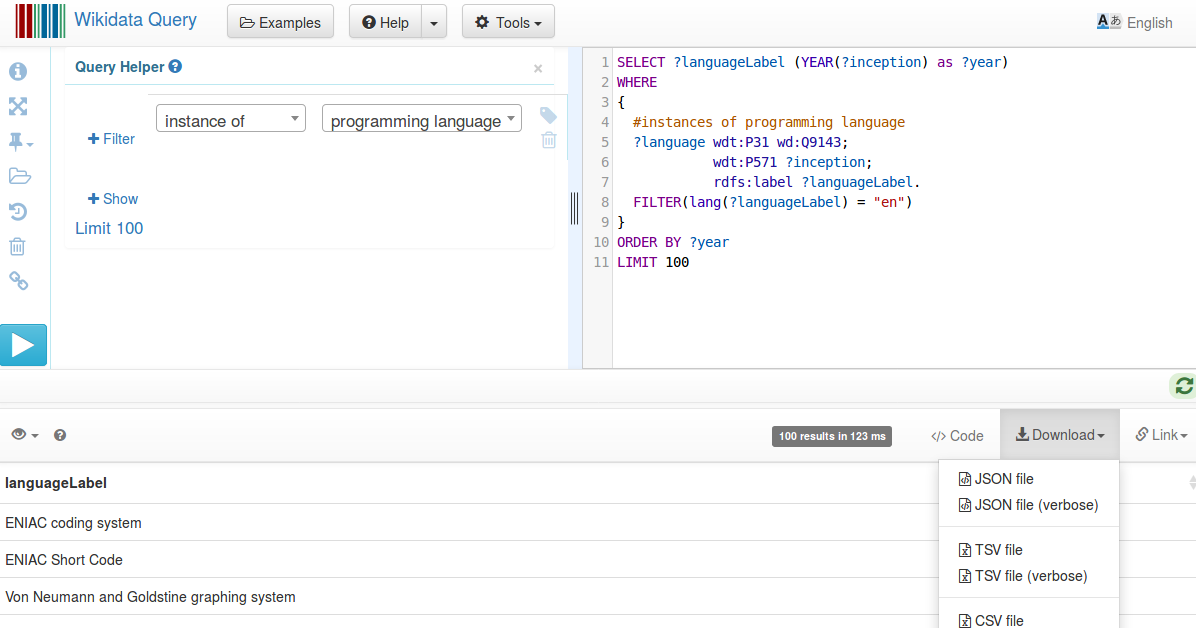
SELECT DISTINCT ?countryLabel ?year ?population
WHERE {
?country wdt:P31 wd:Q6256; #Country
p:P1082 ?populationStatement;
rdfs:label ?countryLabel. #Label
?populationStatement ps:P1082 ?population; #population
pq:P585 ?date. #period in time
FILTER(lang(?countryLabel)="en") #Label in English
BIND(YEAR(?date) as ?year)
FILTER(?year>2000)
}
ORDER by ?countryLabel ?year
Voici une requête SPARQL. Exécutez cette requête sur Wikidata et téléchargez les résultats en format CSV en nommant le fichier countrypopulation.csv.
import numpy as np
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
print(dataset)
3. pandas
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
print(dataframe)
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
print(dataframe.dtypes)
print(dataframe.columns)
print(dataframe.index)
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
print(dataframe.head())
print(dataframe.tail())
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
print(dataframe.head(1))
print(dataframe.tail(1))
4. Sélection de données
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
print(dataframe['year'].value_counts())
print(dataframe['countryLabel'].value_counts())
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
print(dataframe.loc[dataframe['year']==2017])
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
print(dataframe.loc[dataframe['countryLabel'] =="Sweden"])
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
swedenpopulation = dataframe.loc[dataframe['countryLabel'] =="Sweden"]
swedenpopulation2017 = swedenpopulation.loc[swedenpopulation['year'] == 2017]
print(swedenpopulation2017)
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
print(dataframe.loc[(dataframe['year']==2017) & (dataframe['countryLabel'] =="Sweden")])
5. Tri de données
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
population = dataframe.sort_values(by='population')
print(population.head(1))
print(population.tail(1))
6. Analyse de données
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
dataframe2015 = dataframe.loc[dataframe['year']==2015]
print(dataframe2015)
print(dataframe2015.describe(include=[np.int32])['population'])
Exercice 4 ★★★
1. Groupement de résultat
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
groups = dataframe.groupby(['countryLabel']).groups
print(groups.keys())
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
groups = dataframe.groupby(['countryLabel'])
print(groups.first())
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
groups = dataframe.groupby(['countryLabel'])
print(groups.last())
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
groups = dataframe.groupby(['countryLabel'])
print(groups['population'].max())
print(groups['population'].min())
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
groups = dataframe.groupby(['countryLabel'], as_index=False)
print(groups.agg({'population' : max}))
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
groups = dataframe.groupby(['countryLabel'], as_index=False)
print(groups.agg({'population' : min}))
import numpy as np
import pandas as pd
dataset = np.loadtxt("countrypopulation.csv", dtype={'names': ('countryLabel', 'year', 'population'),
'formats': ('<U100', 'i4', 'i')},
skiprows=1, delimiter=",", encoding="UTF-8")
dataframe = pd.DataFrame(dataset, columns=['countryLabel', 'year', 'population'])
groups = dataframe.groupby(['year'], as_index=False)
print(groups.agg({'population' : max}))
Question 1: Exécutez le requête SPARQL ci-dessus sur Wikidata et cette fois téléchargez les résultats en format JSON en nommant le fichier countrypopulation.json. Codez en Python en utilisant pandas afin d'avoir les résultats suivants:
- Calculez la population maximum, minimum et moyenne de chaque pays en 2015
- Calculez la population moyenne, maximum et minimum de chaque pays
- Calculez la population maximum, minimum et moyenne de chaque année pour les pays dont les noms commencent par 'A'
- Tracer un graphique montrant la population de tous les pays en 2015
- Tracer un graphique montrant la population de tous les pays
Indices