Data Science for Chemists
IPL Summer School, CPE Lyon
4. Data Mining
John Samuel
CPE Lyon
Year: 2023-2024
Email: john.samuel@cpe.fr

John Samuel
CPE Lyon
Year: 2023-2024
Email: john.samuel@cpe.fr






.jpg)



.png)


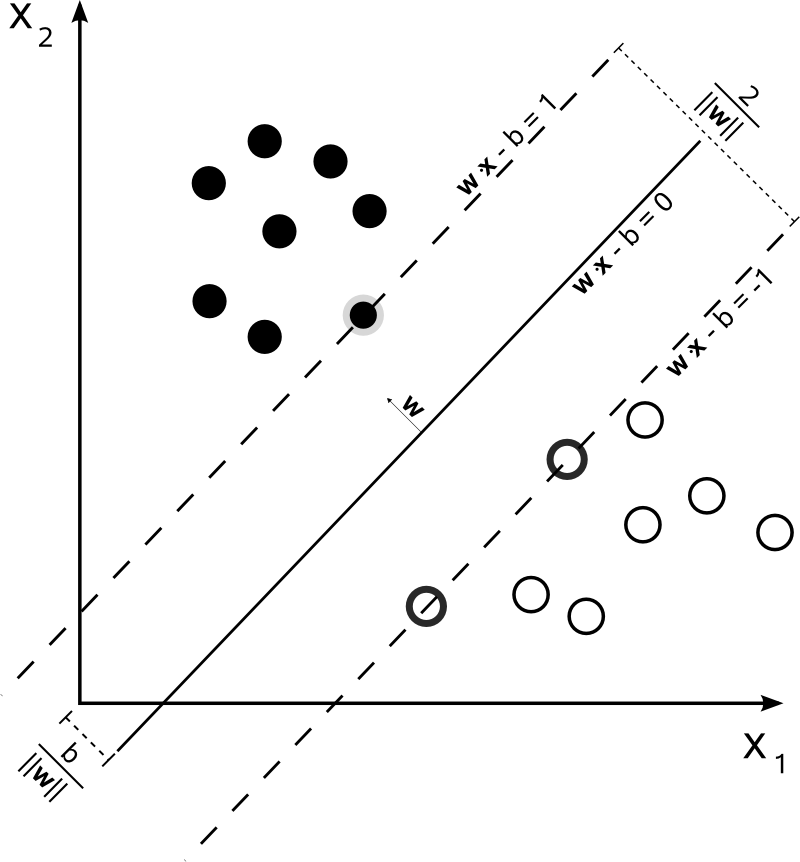
Let
Then



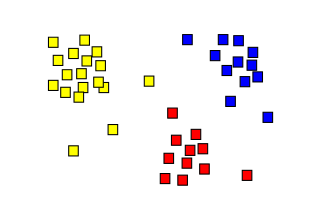
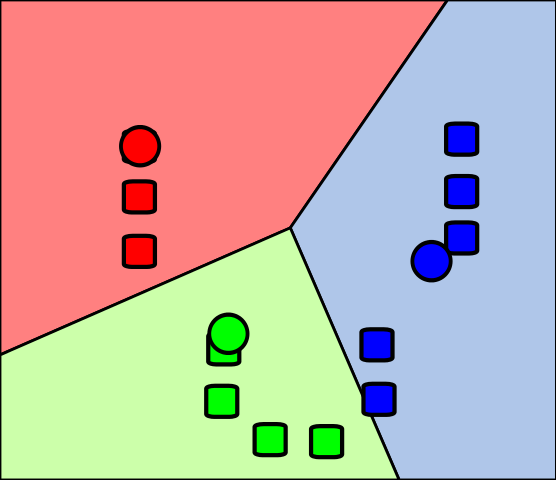




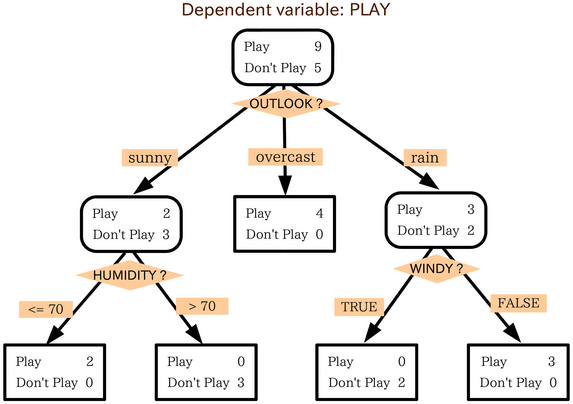
Decision trees are a powerful decision support tool that uses a tree-like model to represent decisions and their possible consequences.