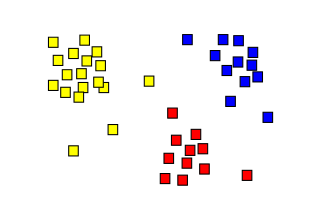
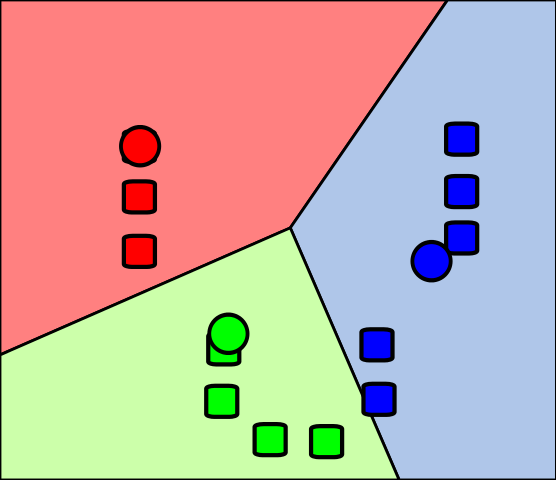
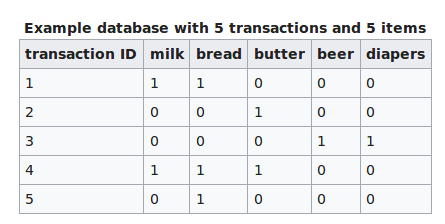
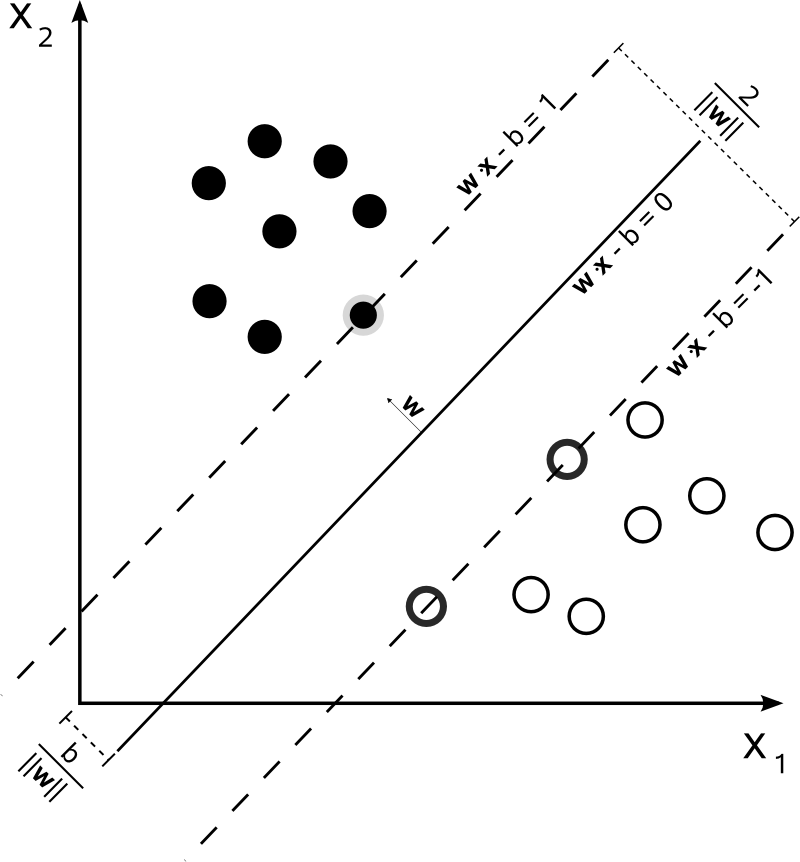
Goal is to detect patterns and regularities in data
Approaches
Supervised learning: Availability of labeled training data
Unsupervised learning: No labeled training data available
Semi-supervised learning: Small set of labeled training data and a large amount
of unlabeled data
1. Patterns
Formalization
Euclidean vector: geometric object with magnitude and direction
Vector space: collection of vectors that can be added together and multiplied by numbers.
Feature vector: n-dimensional vector
Feature space: Vector space associated with the vectors
Examples: Features
Images: pixel values.
Texts: Frequency of occurence of textual phrases.
1. Patterns
Formalization
Feature construction1: construction of new features from already available
features
Feature construction operators
Equality operators, arithmetic operators, array operators (min, max, average etc.)...
Example
Let Year of Birth and Year of Death be two existing features.
A new feature called Age = Year of Birth - Year of Death
https://en.wikipedia.org/wiki/Feature_vector
1. Patterns
Formalization: Supervised learning
Let N be the number of training examples
Let X be the input feature space
Let Y be the output feature space (of labels)
Let {(x1, y1),...,(xN, yN)} be
the N training examples, where
xi is the feature vector of ith training example.
yi is its label.
The goal of supervised learning algorithm is to find g: X → Y, where
g is one of the functions from the set of possible functions G (hypotheses
space)
Scoring function F denote the space of scoring functions, where
f: X × Y → R such that g returns the
highest scoring function.
1. Patterns
Formalization: Unsupervised learning
Let X be the input feature space
Let Y be the output feature space (of labels)
The goal of unsupervised learning algorithm is to
find mapping X → Y
1. Patterns
Formalization: Semi-supervised learning
Let X be the input feature space
Let Y be the output feature space (of labels)
Let {(x1, y1),...,(xl, yl)} be the
l be the set of labeled training examples
Let {xl+1,...,xl+u} be the u be the set of unlabeled
feature vectors of X.
The goal of semi-supervised learning algorithm is to do
Transductive learning, i.e., find correct labels for
{xl+1,...,xl+u}. OR
Inductive learning, i.e., find correct mapping X → Y
2. Data Mining
Tasks in Data Mining
Classification
Clustering
Regression
Sequence Labeling
Association Rules
Anomaly Detection
Summarization
2.1. Classification
Generalizing known structure to apply to new data
Identifying the set of categories to which an object belongs
Binary vs. Multiclass classification
2.1. Classification
Applications
Spam vs Non-spam
Document classification
Handwriting recognition
Speech Recognition
Internet Search Engines
2.1. Classification
Formal definition
Let X be the input feature space
Let Y be the output feature space (of labels)
The goal of classification algorithm (or classifier) is to find
{(x1, y1),...,(xl, yk)}, i.e., assigning a
known label to every input feature vector, where
xi ∈ X
yi ∈ Y
|X| = l
|Y| = k
l >= k
2.1. Classification
Classifiers
Classifying Algorithm
Two types of classifiers:
Binary classifiers assigning an object to any of two classes
Multiclass classifiers assigning an object to one of several classes
2.1. Classification
Linear Classifiers
A linear function assigning a score to each possible category by combining the feature vector of
an instance with a vector of weights, using a dot product.
Formalization:
Let X be the input feature space and xi ∈
X
Let βk be vector of weights for category k
score(xi, k) = xi.βk,
score for assigning category k to instance xi. The
category that gives the highest score is assigned as the category of the instance.
2.2. Clustering
Discovering groups and structures in the data without using known structures in the data
Objects in a cluster are more similar to each other than the objects in the other cluster
2.2. Clustering
Applications
Social network analysis
Image segmentation
Recommender systems
Grouping of shopping items
2.2. Clustering
Formal definition
Let X be the input feature space
The goal of clustering is to find k subsets of X, in such a way that
C1.. ∪ ..Ck ∪ Coutliers = X
and
Ci ∩ Cj = ϕ, i ≠ j; 1 <i,j <k
Coutliers may consist of outlier instances (data anomaly)
2.2. Clustering
Cluster models
Centroid models: cluster represented by a single mean vector
Connectivity models: distance connectivity
Distribution models: clusters modeled using statistical distributions
Density models: clusters as connected dense regions in the data space
Subspace models
Group models
Graph-based models
Neural models
2.3. Regression
Finding a function which models the data
Assigns a real-valued output to each input
Estimating the relationships among variables
Relationship between a dependent variable ('criterion variable') and one or more independent
variables ('predictors').
2.3. Regression
Applications
Prediction
Forecasting
Machine learning
Finance
2.3. Regression
Formal definition
A function that maps a data item to a prediction variable
Let X be the independent variables
Let Y be the dependent variables
Let β be the unknown parameters (scalar or vector)
The goal of regression model is to approximate Y with
X,β, i.e.,
Y ≅ f(X,β)
2.3. Regression
Linear regression
straight line: yi = β0 + β1xi +
εi OR
parabola: yi = β0 + β1xi +
β1xi2 +εi
2.3. Regression
Linear regression
straight line: yi = β0 + β1xi +
εi OR
ŷi = β0 + β1i OR
Residual: ei = ŷi - yi
Sum of squared residuals, SSE = Σ ei, where 1 < i < n
The goal is to minimize SSE
2.4. Sequence Labeling
Assigning a class to each member of a sequence of values
2.4. Sequence Labeling
Applications
Part of speech tagging
Linguistic translation
Video analysis
Handwriting recognition
Information extraction
2.4. Sequence Labeling
Formal definition
Let X be the input feature space
Let Y be the output feature space (of labels)
Let 〈x1,...,xT〉 be a sequence of length T.
The goal of sequence labeling is to generate a corresponding sequnce
〈y1,...,yT〉 of labels
xi ∈ X
yj ∈ Y
2.5. Association Rules
Association Rules
Searches for relationships between variables
2.5. Association Rules
Applications
Web usage mining
Intrusion detection
Affinity analysis
2.5. Association Rules
Formal definition
Let I be a set of n binary attributes called items
Let T be a set of m transactions called database
Let I = {(i1,...,in)} and T =
{(t1,...,tm)}
The goal of association rule learning is to find
X ⇒ Y, where X ⇒ Y ⊆
I
X is the antecedent
Y is the consequent
2.5. Association Rules
Formal definition
Support: how frequently an itemset appears in the database
supp(X) = |t ∈T; X ⊆ t| / |T|
Confidence: how frequently the rule has been found to be true.
conf(X ⇒ Y) = supp(X ∪ Y)/supp(X)
Lift: the ratio of the observed support to that of the expected if X and Y were independent
lift(X ⇒ Y) = supp(X ∪ Y)/(supp(X)
⨉ supp(Y))
2.5. Association Rules
Example
{bread, butter} ⇒ {milk}
2.6. Anomaly Detection
Identification of unusual data records
Approaches
Unsupervised anomaly detection
Supervised anomaly detection
Semi-supervised anomaly detection
2.6. Anomaly Detection
Applications
Intrusion detection
Fraud detection
Remove anomalous data
System health monitoring
Event detection in sensor networks
Misuse detection
2.6. Anomaly Detection
Characteristics
Unexpected bursts
2.6. Anomaly Detection
Formalization
Let Y be a set of measurements
Let PY(y) be a statistical model for the distribution of
Y under 'normal' conditions.
Let T be a user-defined threshold.
A measurement x is an outlier if PY(x) < T
2.7. Summarization
Providing a more compact representation of the data set
Report Generation
2.7. Summarization
Applications
Keyphrase extraction
Document summarization
Search engines
Image summarization
Video summarization: Finding important events from videos
2.7. Summarization
Formalization: Multidocument summarization
Let {D = D1, ..., Dk} be a document collection of k
documents
A Document {D = t1, ..., tm} consists of m textual units (words,
sentences, paragraphs etc.)
Let {D = t1, ..., tn} be the complete set of all textual
units from all documents, where
ti ∈ D, if and only if ∃ Dj such
that ti ∈ Dj
S ⊆ D constitutes a summary
Two scoring functions
Rel(i): relevance of textual unit i in the summary
Red(i,j): Redundancy between two textual units ti,
tj
Extraction: Selecting a subset of existing words, phrases, or sentences in the
original text without any modification
Abstraction: Build an internal semantic representation and then use natural
language generation techniques
2.7. Summarization
Extractive summarization
Approaches
Generic summarization: Obtaining a generic summary
Query relevant summarization: Summary relevant to a query
3. Algorithms
Support Vector Machines (SVM)
Stochastic Gradient Descent (SGD)
Nearest-Neighbours
Naive Bayes
Decision Trees
Ensemble Methods (Random Forest)
3.1. Support Vector Machines (SVM)
Introduction
Supervised learning approach
Binary classification algorithm
Constructs a hyperplane ensuring the maximum separation between two classes
3.1. Support Vector Machines (SVM)
Hyperplane
Hyperplane of n-dimensional space is a subspace of dimension n-1
Examples
Hyperplane of a 2-dimensional space is 1-dimensional line
Hyperplane of a 3-dimensional space is 2-dimensional plane
3.1. Support Vector Machines (SVM)
Formal definition
The goal of a SVM is to estimate a function f: RN ⨉ {+1,-1}, i.e.,
If x1,...,xl ∈ RN are the N
input data points,
the goal is to find
(x1,y1),...,(xl,yl) ∈
RN ⨉ {+1,-1}
Any hyperplane can be written by the equation using set of input points x
w.x - b = 0, where
w ∈ RN, a normal vector to the plane
b ∈ R
A decision function is given by f(x) = sign(w.x - b )
Normal vector
3.1. Support Vector Machines (SVM)
Formal definition
If the training data are linearly separable, two hyperplanes can be selected
They separate the two classes of data, so that distance between them is as large as possible.
The hyperplanes can be given by the equations
w.x - b = 1
w.x - b = -1
The distance between the two hyperplanes can be given by 2/||w||
Region between these two hyperplanes is called margin.
Maximum-margin hyperplane is the hyperplane that lies halfway between them.
3.1. Support Vector Machines (SVM)
Formal definition
In order to prevent data points from falling into the margin, following constraints are added
w.xi - b >= 1, if yi = 1
w.xi - b <= -1, if yi = -1
yi(w.xi - b) >= 1 for 1<= i <= n
The goal is to minimize ||w|| subject to yi(w.xi -
b) >= 1 for 1<= i <= n
Solving for both w and b gives our classifier
f(x) = sign(w.x - b)
Max-margin hyperplane is completely determined by the points that lie nearest to it, called the
support vectors
3.1. Support Vector Machines (SVM)
Data mining tasks
Classification (Multi-class classification)
Regression
Anomaly detection
3.1. Support Vector Machines (SVM)
Applications
Text and hypertext categorization
Image classification
Handwriting recognition
3.2. Stochastic Gradient Descent (SGD)
A stochastic approximation of the gradient descent optimization
Iterative method for minimizing an objective function that is written as a sum of differentiable
functions.
Finds minima or maxima by iteration
3.2. Stochastic Gradient Descent
Gradient
Multi-variable generalization of the derivative.
Gives slope of the tangent of the graph of a function
Gradient points in the direction of the greatest rate of increase of a function
Magnitude of gradient is the slope of the graph in that direction
3.2. Stochastic Gradient Descent
Gradient vs Derivative
Derivatives defined on functions of single variable
Gradient defined on functions of multiple variables
Gradient is a vector-valued function (range is a vector)
Derivative is a scalar-valued function
3.2. Stochastic Gradient Descent
Gradient descent
First-order iterative optimization algorithm for finding the minimum of a function.
Finding a local minima involves taking steps proportional to the negative of the gradient
of the function at the current point.
3.2. Stochastic Gradient Descent
Standard gradient descent method
Let's take the problem of minimizing an objective function
Q(w) = 1/n (ΣQi(w)), 1<=i<n
Summand function Qi associated with ith observation
in the data set.
w = w - η.∇ Q(w)
3.2. Stochastic Gradient Descent
Iterative method
Choose an initial vector of parameters and learning rate η.
Repeat until an approximate minimum is obtained:
Randomly shuffle examples in the training set.
w = w - η.∇ Qi(w), for i=1...n
3.2. Stochastic Gradient Descent
Applications
Classification
Regression
3.3. Nearest-Neighbours
k-nearest neighbors algorithm
k-NN classification: output is a class membership
(object is classified by a majority vote of its neighbors.)
k-NN regression: output is the property value for the object
(average values of its k nearest neighbors)
3.3. Nearest-Neighbours
Applications
Regression
Anomaly detection
3.4. Naive Bayes classifiers
Collection of simple probabilistic classifiers based on applying Bayes' theorem with strong
independence assumption between the features.
3.4. Naive Bayes classifiers
Applications
Document classification (spam/non-spam)
3.4. Naive Bayes classifiers
Bayes' Theorem
If A and B are events.
P(A), P(B) are probabilities of observing A and B independently of each other..
P(A|B) is conditional probability, the likelihood of event A occurring given that B is true
P(B|A) is conditional probability, the likelihood of event B occurring given that A is true
P(B) ≠ 0
P(A|B) = (P(B|A).P(A))/P(B)
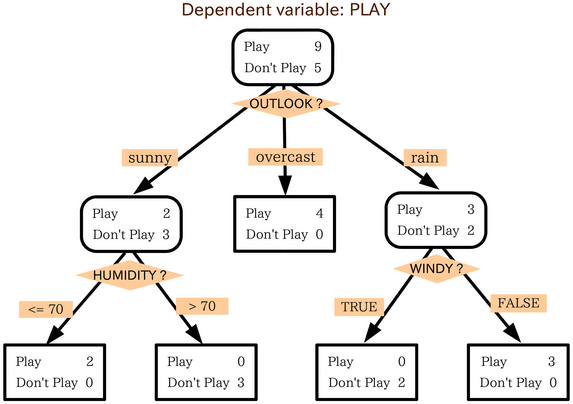
3.5. Decision Trees
Decision support tool
Tree-like model of decisions and their possible consequences
3.5. Decision Trees
Applications
Classification
Regression
Decision Analysis: identifying strategies to reach a goal
Operations Research
3.6. Ensemble Methods (Random Forest)
Defintion
Collection of multiple learning algorithms to obtain better predictive performance than could be
obtained from one of the constituting algorithms alone.
Random forests are obtained by building multiple decision trees at training time
3.6. Ensemble Methods (Random Forest)
Multiclass classification
Multilabel classification (the problem of assigning one or more label to each instance. There is
no limit on the number of classes an instance can be assigned to.)
Regression
Anomaly detection
4. Feature Selection
Definition
Process of selecting a subset of relevant features
Used in domains with large number of features and comparatively few sample points
4. Feature Selection
Applications
Analysis of written texts
Analysis of DNA microarray data
4. Feature Selection
Formal defintion[8]
Let X be the original set of n features, i.e., |X| = n
Let wi be the weight assigned to feature xi∈ X
Binary feature selection assigns binary weights whereas continuous feature selection assigns
weights preserving the order of its relevance.
Let J(X') be an evaluation measure, defined as J: X' ⊆ X → R
Feature selection problem may be defined in three following ways
|X'| = m < n. Find X' ⊂ X such that J(X') is
maximum
Choose J0, Find X' ⊆ X, such that J(X') >=
J0
Find a compromise among minimizing |X'| and maximizing J(X')
References
Research articles
From data mining to knowledge discovery in databases, Usama Fayyad, Gregory Piatetsky-Shapiro,
and Padhraic Smyth, AI Magazine Volume 17 Number 3 (1996)
Survey of Clustering Data Mining Techniques, Pavel Berkhin
Mining association rules between sets of items in large databases, Agrawal, Rakesh, Tomasz
Imieliński, and Arun Swami. Proceedings of the 1993 ACM SIGMOD international conference on
Management of data - SIGMOD 1993. p. 207.
Comparisons of Sequence Labeling Algorithms and Extensions, Nguyen, Nam, and Yunsong Guo.
Proceedings of the 24th international conference on Machine learning. ACM, 2007.
An Analysis of Active Learning Strategies for Sequence Labeling Tasks, Settles, Burr, and Mark
Craven. Proceedings of the conference on empirical methods in natural language processing.
Association for Computational Linguistics, 2008.
References
Research articles
Anomaly detection in crowded scenes, Mahadevan; Vijay et al. Computer Vision and Pattern
Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010
A Study of Global Inference Algorithms in Multi-Document Summarization. McDonald, Ryan. European
Conference on Information Retrieval. Springer, Berlin, Heidelberg, 2007.
Feature selection algorithms: A survey and experimental evaluation., Molina, Luis Carlos, Lluís
Belanche, and Àngela Nebot. Data Mining, 2002. ICDM 2003. Proceedings. 2002 IEEE International
Conference on. IEEE, 2002.
Support vector machines, Hearst, Marti A., et al. IEEE Intelligent Systems and their
applications 13.4 (1998): 18-28.







.jpg)



.png)