
Recommendation System#
Two approaches to build a recommendation system with some common processes are :
Classfication Algorithms
Clustering Algorithms
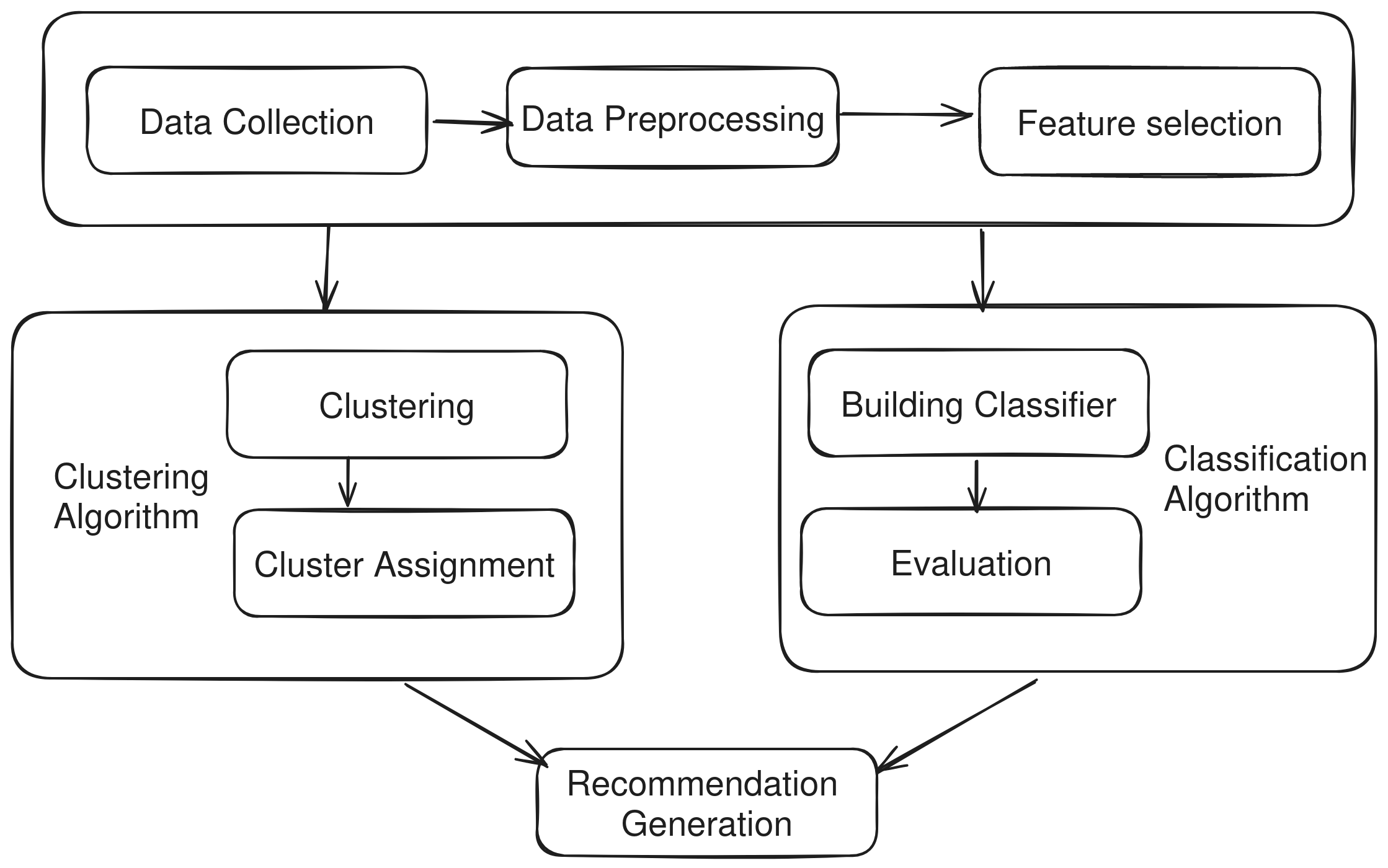
Using Clustering algorithm#
from sklearn.cluster import KMeans
from sklearn.preprocessing import LabelEncoder
import pandas as pd
# Sample data
data = [
["green", "nature", "thumbnail", "landscape"],
["blue", "architecture", "medium", "portrait"],
["blue", "people", "medium", "landscape"],
["yellow", "nature", "medium", "portrait"],
["green", "nature", "thumbnail", "landscape"],
["blue", "people", "medium", "landscape"],
["blue", "nature", "thumbnail", "portrait"],
["yellow", "architecture", "thumbnail", "landscape"],
["blue", "people", "medium", "portrait"],
["yellow", "nature", "medium", "landscape"],
["yellow", "people", "thumbnail", "portrait"],
["blue", "people", "medium", "landscape"],
["red", "architecture", "thumbnail", "landscape"],
]
# Encode categorical features
label_encoders = [LabelEncoder() for _ in range(len(data[0]))]
encoded_data = []
for i, column in enumerate(zip(*data)):
encoded_data.append(label_encoders[i].fit_transform(column))
X = list(zip(*encoded_data)) # Features
# Clustering
k = 2 # Number of clusters
kmeans = KMeans(n_clusters=k, n_init=10)
kmeans.fit(X)
clusters = kmeans.labels_
# Add cluster labels to the original data
data_with_clusters = pd.DataFrame(data, columns=["Color", "Category", "Size", "Type"])
data_with_clusters["Cluster"] = clusters
# Recommendation function
def recommend_items(cluster, data_with_clusters):
items_in_cluster = data_with_clusters[data_with_clusters["Cluster"] == cluster]
recommended_items = items_in_cluster.sample(n=3) # Sample 3 items from the cluster
return recommended_items
# Example usage
user_interaction = ["green", "nature", "thumbnail", "landscape"] # Assuming user interacted with this item
encoded_interaction = [label_encoders[i].transform([val])[0] for i, val in enumerate(user_interaction)]
cluster = kmeans.predict([encoded_interaction])[0]
recommendations = recommend_items(cluster, data_with_clusters)
print("Recommended items:")
print(recommendations)
Recommended items:
Color Category Size Type Cluster
8 blue people medium portrait 0
0 green nature thumbnail landscape 0
6 blue nature thumbnail portrait 0
Using classification algorithm#
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
# Sample data
data = [
["green", "nature", "thumbnail", "landscape"],
["blue", "architecture", "medium", "portrait"],
["blue", "people", "medium", "landscape"],
["yellow", "nature", "medium", "portrait"],
["green", "nature", "thumbnail", "landscape"],
["blue", "people", "medium", "landscape"],
["blue", "nature", "thumbnail", "portrait"],
["yellow", "architecture", "thumbnail", "landscape"],
["blue", "people", "medium", "portrait"],
["yellow", "nature", "medium", "landscape"],
["yellow", "people", "thumbnail", "portrait"],
["blue", "people", "medium", "landscape"],
["red", "architecture", "thumbnail", "landscape"],
]
result = [
"Favorite",
"NotFavorite",
"Favorite",
"Favorite",
"Favorite",
"Favorite",
"Favorite",
"NotFavorite",
"NotFavorite",
"Favorite",
"Favorite",
"NotFavorite",
"NotFavorite",
]
# Encode categorical features and labels
label_encoders = [LabelEncoder() for _ in range(len(data[0]))]
encoded_data = []
for i, column in enumerate(zip(*data)):
encoded_data.append(label_encoders[i].fit_transform(column))
X = list(zip(*encoded_data)) # Features
y = result # Labels
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train the logistic regression classifier
classifier = svm.SVC()
classifier.fit(X_train, y_train)
# Predictions
y_pred = classifier.predict(X_test)
# Evaluate the classifier
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
# Sample prediction
sample_item = ["green", "nature", "thumbnail", "landscape"] # Sample item attributes
encoded_item = [label_encoders[i].transform([val])[0] for i, val in enumerate(sample_item)]
prediction = classifier.predict([encoded_item])[0]
print(f"Prediction for the sample item: {prediction}")
Accuracy: 0.6666666666666666
Prediction for the sample item: Favorite